AI 能“深度研究”了,但我还是离不开百度和Google
本文来自微信公众号:APPSO (ID:appsolution),作者:发现明日产品的,原文标题:《AI 能「深度研究」了,但我还是离不开百度和 Google》
在一轮轮AI基础建设起来之后,目前率先卷起来的应用场景,是「深度研究」。
更准确、更针对、更深入,看到「深度研究」卷成这样,不禁要大呼:完了,搜索引擎都别干了。
别急,还未必就这样。
Semrush是一个监测网站的访问流量变化的平台,数字营销及SEO在调研中发现,Semrush统计显示,被认为最容易受到AI威胁的维基百科,流量实际上并没有如预期般走低。
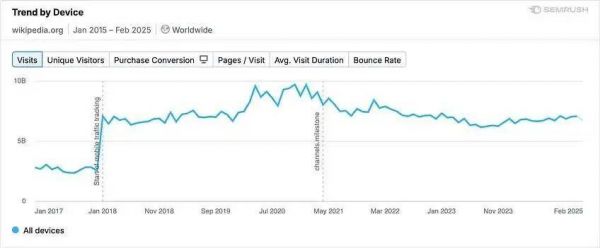
月均访问量仍然有50亿次,谁说的Wikipedia马上就要被AI干掉了?
甚至不同于搜索引擎,支持关键词又支持完整句,维基百科是一个「词条」导向的检索方式,纯复古。
AI搜索不断进化的过程,实际也在不断证明Wikipedia的重要性,或者说内容来源的重要性。
幻觉横行的旧版本
早期把AI应用到搜索场景中时,它的幻觉是一个严重的问题。尤其是预训练和参数量被视为唯二法则的时候,LLM有时会给出行文上看起来合理,但实则虚假的回答。
「一本正经地胡说八道」是最常见的形容。比如,去年两位纽约律师遭到了法庭制裁,因为他们提交的文书中,有六个案件引文完全不存在,是律师们在用GPT生成时,模型凭空捏造出来的。
这个例子多少有点离谱,却很典型:在早期AI搜索没有被质疑的时候,引用链接还不是常见的设计,导致AI直接给出的单一答案往往缺乏透明度,很难核查。
这对于某些领域的工作而言是非常致命的。2022年,Meta曾经发布过一版名为「Galactica」的模型,主打科研场景,但没几天就被科研人员大量投诉,Meta不得不紧急撤回一个发布。
相比之下,传统搜索引擎的排列,有一套规则和判断方式。以Google去年发布的Google’s Search Quality Rater Guidelines中,提出了一套「EEAT」法则:
简而言之就是,经验、专业性、权威性、可信度,这四个维度,共同构成了Google抓取内容时的标准。同时,平台还会根据用户反馈,调整页面排名,使低质内容沉底。这些机制,都对错误信息和低质内容起到了过滤的效果,从而保障整体信息质量。
当然,不能忽略的是,当竞价广告成为传统搜索引擎的主要收入来源之后,这一套机制也要对营收妥协。
不过,传统搜索引擎的形态在很长一段时间内没有发生变化。而AI搜索,在过去一两年里快速进步,在形态上发生了翻天覆地的改变。
有「深度研究」就可以不核查了吗?
今年才过去三个月,主流的大模型厂商纷纷推出Deep Research服务。从OpenAI、DeepSeek,到刚推出不久的Grok 3,以及曾经的弄潮儿Perplexity,「深度研究」成了一时间,家家都在卷的功能。
所有的Deep Research都有一点共性:内容有来源,且来源可追溯。
在以往,AI生成的回答就是一个完整的段落,让人没法核查。有些即便提供了引用来源,溯源依然有很大的难度。
比如,模型罗列了一大堆网站和文档,但实际只用了其中一小部分内容。或者给出的回答主要靠数据集的「记忆」来生成,而非检索到的文档。
而作为Deep Research模式的基本操守,来源是必须有的。在ChatGPT的Deep Research中,会文内显示来源网站的域名。
Grok 3里面是在思考过程里列出网址,报告正文有时候会触发出文内引用,有时候没有,看情况。
Perplexity的方式是数字角标,鼠标悬停时会显示一段介绍网页内容的话。
如果你是老网民,大概率还保留着对域名的敏感。能辨别对.org.edu.gov这类后缀的潜台词:这是来自机构的网页,有更高的可信度。
像上面Perplexity的例子,就是来自商务部的专栏。
Deep Research加强了内容来源的透明度,这是符合用户习惯的:在搜索信息时,用户不仅要求答案准确,还要求过程透明、结果可验。
到这一步为止,好像都还看不出什么变化:这不都能在站内解决?还有搜索引擎什么事儿吗?
有的,甚至不只是传统搜索引擎,而是核查这个工作,并不是看看网页是不是非法站点就完成了的——这恰恰让人更加无法放弃传统搜索引擎。
AI搜索节省的是在搜索引擎的列表上,一路点开、查看的操作时间。如果你有一个明确熟悉的领域,效率的提升其实有限。就像PubMed之于医学生,arxiv之于技术人员,github之于程序员,等等等,简直像「家」一般熟悉。
但这个环节,像是把大块的石头放进瓶子里:两三块可能就塞不下了,却还是有很多空间可以放倒碎石。碎石也倒不了了,还可以倒细沙,直到把瓶子里的每一寸空间都填满。
这些碎石细沙,相当于需要长尾查询的信息,这往往涉及非常具体的细节或小众的知识点——你只能自己判断。
这种场景下,AI的优势变成了劣势。被高度浓缩和提炼过的信息,没有足够的广度和多样性,反而限制了做判断时的动作幅度。
比方说你想了解一下最新的小米15 Ultra,「了解」二字的背后其实涉及了很多层面:它价格多少、什么时候上市、与你现在的手机相比如何、它的售价相对于你的银行存款如何、预售排队吗……等等等等。
购买决策是一个复杂的链条,它涉及到外部对比和内部对比,外部对比可以只看同类产品的竞争力,但内部对比就要考虑自己使用、偏好等各种情况——前者可以有AI帮忙,后者就纯靠自己拿捏了。
你要对着chatbot把自己的家底都唠清楚吗?很难。你要把自己的微信支付账单上传给AI,让它分析你的财务实力吗?很难。
千头万绪,你最想要了解的,还是汇成了两个关键字:「小米Ultra」「价格」。
然而这些具体又小众的信息点,并不是人人都能用精准的语言描述出来的。它仍然是一个关键字探查之旅:你最想了解的东西,就是你打出的那个关键字。
有这么一个说法:遇事不决抛硬币的时候,抛出那一刻、硬币尚未落地时,你心中冒出的念头,就是你在找的答案。
在搜索引擎上检索,就是在抛硬币,一次不行抛两次,两次不行抛三次,直到搜集足够多的细沙,把石头的空隙填满。
各类「深度研究」很好用,以后也会越来越好用,但眼下我还不能没有搜索引擎。
我们正在招募伙伴
简历投递邮箱
hr@ifanr.com
✉️邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)
相关推荐
微软 vs Google:AI技术的王权更迭
这段涉及百度的AI秘史,说明AI注定是一场中美的"新军备竞赛"
诺贝尔奖连续“颁给AI”,背后最大赢家竟是Google?
Google已经被OpenAI超越了吗?
韬光养晦的Sony AI,凭什么与Google和Facebook平起平坐?
GPT之父Ilya最新斯坦福访谈全文:AI意识,开源和OpenAI商业化,AI研究的未来
投资应该深度研究,还是广度覆盖?
从此,Google再无Brain
Google 创始人谢尔盖·布林回归,直面 Gemini、Google、AGI 若干问题
Ilya官宣离职,OpenAI还是走散了
网址: AI 能“深度研究”了,但我还是离不开百度和Google http://www.xishuta.com/newsview133821.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



