“AI登月时刻”,OpenAI模型摘取奥数金牌
OpenAI的一个通用推理模型,在刚结束的国际奥林匹克数学竞赛(IMO)中达到了金牌的水平。AI登月时刻,社交媒体一夜无眠,AI圈子沸腾了。
在与人类参赛者完全相同的规则下,OpenAI的模型挑战了2025年IMO试题:两场各4.5小时的考试、禁用任何工具和互联网、只能阅读官方题面并以自然语言撰写完整证明。模型完整解出了6题中的5题。每道题都由三位前IMO奖牌得主独立批改,并在取得一致意见后定分。最终模型拿到35/42分——足以摘金!
重大意义在于,这是一个通用推理模型,而不是一个专门用来解数学题的专门系统,也没有经过验证的奖励信号,即它不是依赖于“有标准答案、实时打分的奖励”来学会的,而是靠更通用的推理和新技术,在长时间复杂的过程中,做出了正确的推理和证明。
OpenAI证明,尽管经历了Meta疯狂的挖角,它依然保持了顶尖研究人才的密度,做出重大的研究突破。本周OpenAI的模型o3 alpha在AtCoder世界巡回赛2025决赛中仅逊于人类编程奇才Psyho,获得第二名;测试中强于o3 pro,是最好的编程及物理模型。
这样,OpenAI目前拥有了最强的编程及数学模型,让它再次碾压DeepMind,Anthropic,Grok等,也再次与中国引领的开源模型拉开了差距。
实际上,OpenAI内部正在测试一个全新的推理模型,取得奥数金牌成绩,仅是其一次小试牛刀。它的正式发布甚至会在GPT-5之后,预计是今年底。OpenAI推理研究的科学家Alexander We负责这个模型项目,他首先宣布了这一消息,并顺带提及GPT-5发布在即。
这是一件大事,我们可以说它让成为AGI迈向ASI的新起点吗?Alexander Wei发了一组帖文说明它的意义:
“第一,IMO题目对“持续创造性思考”提出了前所未有的要求。从推理时间跨度来看,我们已经一路从GSM8K(顶尖人类约0.1分钟)→MATH数据集(约1分钟)→AIME(约10分钟)→IMO(约100分钟)。
第二,IMO答案往往是长达数页、难以验证的证明。要想在这一关取得进展,就必须跳出传统强化学习“奖励信号清晰、易于验证”的范式。我们做到了——由此得到的模型能够在复杂度和严谨性上匹敌人类数学家。
除了结果本身,我更兴奋的是方法:我们并未依赖狭窄的、任务特化的技巧,而是通过通用强化学习与“测试时计算”扩展的新突破,才达到这一水准。”
这项成就,在OpenAI内部被认为是实现了急需的一次研究上的突破,“Alex Wei做到了。”它几乎没有针对IMO做任何专项工作,只是持续训练通用模型;所有证明均为自然语言撰写,没有使用任何定制化的评测框架。
这个模型的尺寸仍然是个谜,不过OpenAI的团队成员透露,所用的算力相当有限,因为星际之门还没有投入使用。
OpenAI科学家Sebastined Bubeck称之为AI的“登月时刻”。简单讲:一个只是预测下一个词的机器(真的是啥工具都没用)刚刚给出了几个又难又新的数学题的创造性证明,这种水平平时也只有少数天才少年能做到。

OpenAI的首席研究官Mark Chen曾经担任美国国际奥林匹克信息竞赛的教练,他认为:“不同于以往比赛中用的那些狭窄的系统,我们的模型具备更广泛的推理能力,远远超越了竞赛题的范围。”
他指的是谷歌的AlphaProof在去年的奥数赛中,解出了6道题中的4道。
解决了奥数金牌的问题,接下来就是人类真正待解的难题了。在OpenAI多智能体组的研究员Sheryl Hsu参与了这个项目,她激动地说,从起步到达到奥数金牌水平,仅用了15个月,照这个速度下去,明年就可以用来产生数学定理和用全新方法进行数学研究了。
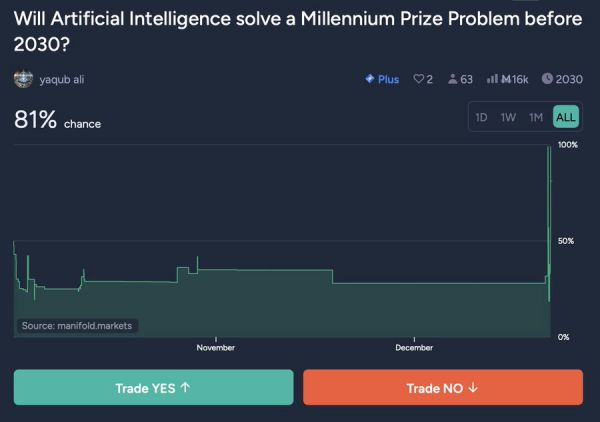
人工智能会在2030年前解决一个千禧年大奖难题吗?当前市场上对这个问题的预测概率骤然上升,达到了81%。
千禧年大奖难题是指克雷数学研究所(Clay Mathematics Institute)于2000年提出的七个尚未解决的重要数学问题,每个问题的奖金是100万美元。
GPT-5
万众期待的GPT-5要来了。奥特曼宣布:
我们很快就会发布GPT-5,但也希望大家对它抱有合理的预期:这是一个实验性的模型,融入了我们将在未来模型中继续采用的新研究技术。
我们相信你们会喜欢GPT-5,但在接下来的几个月里,我们并不打算发布一个具备IMO金牌水平能力的模型。
有一种说法是这次发布就是为了终结命名混乱,将转用一个统一模型架构,用户只要“挑/调”推理强度或智能等级即可。
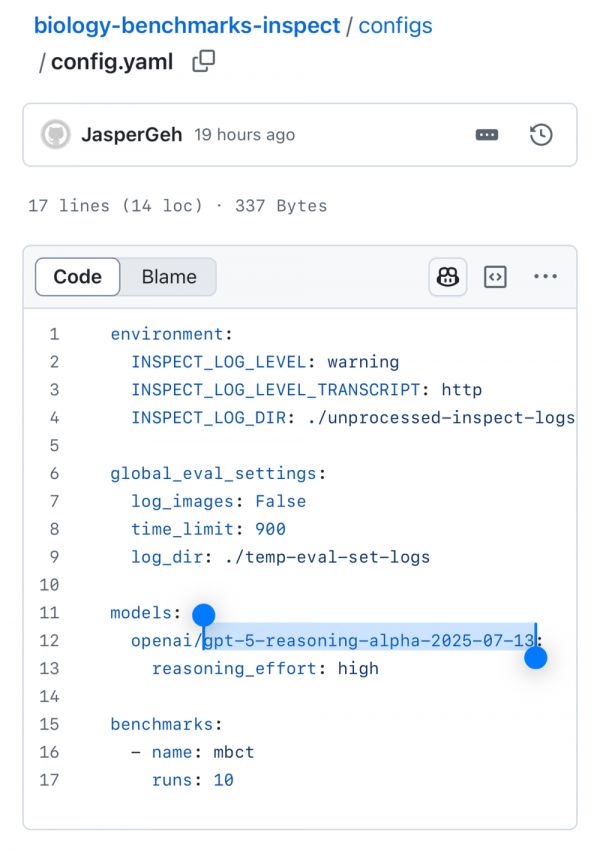
圈子里也在流传GPT-5的蛛丝马迹。这张图显示GPT-5在测试生物风险,用的是最强推理模式,限时15分钟,连跑10次mbct生物题,把结果和日志按指定目录收好。
一些AI研究者分析:GPT-5将采用end-to-end强化学习(RL)进行训练,模型直接在环境中从原始输入学习到最优策略,无需人为拆分子任务或设计中间模块,也不依赖于显式的chain of thought(逐步推理)输出。通过整体性的奖励信号指导,模型能够高效地探索、试错并收敛到优秀的解决方案,实现更高的任务完成度和更强的泛化能力。
最近OpenAI被Meta挖角,几乎伤筋动骨。但这次奥数夺金,等于是告诉Meta:我们要向超级人工智能跨越了。
最后,下面是OpenAI负责推理研究的Noam Brown的评论:
今天,我们@OpenAI取得了一个许多人认为还需要几年才能实现的里程碑:一个具备金牌水平的推理型大语言模型(LLM),在2025年国际数学奥林匹克(IMO)中,在与人类相同的时间限制下、无需任何工具,完成了解题。
听起来已经很惊人了,但这个成就的意义其实远不止这个标题所能表达的:
通常来说,像围棋、Dota、扑克、外交游戏(Diplomacy)等领域的AI结果,研究人员要花费数年时间,打造一个只擅长某个狭窄领域、除此之外几乎一无是处的AI。
但这次并不是一个专门针对IMO的模型,而是一个融合了全新实验性通用技术的推理型LLM。
那么,有什么不同呢?我们开发了新的技术,让LLM在那些难以验证的任务上表现得更好。IMO题目正是绝佳的挑战:证明通常长达数页,专家们也需要几个小时才能批改。相比之下,AIME(美国数学邀请赛)的答案只是0到999之间的一个整数。
此外,这个模型会“思考”很久。o1思考几秒,Deep Research思考几分钟,而它可以思考几个小时。更重要的是,它的思考效率也更高。而且,在推理时间计算和效率上,我们还有很大的提升空间。
值得回顾的是,AI尤其是在数学领域的进步有多么快。2024年时,AI实验室还在用小学数学(GSM8K)作为模型发布的评测。随后我们达到了高中水平的MATH基准,又突破了AIME,如今则达到了IMO金牌水平。
接下来会怎样?尽管最近AI进步飞快,我完全相信这个趋势还会继续。更重要的是,我认为我们正接近让AI在科学发现中发挥实质性作用的阶段。因为AI的表现从略低于顶尖人类水平到略高于顶尖人类水平之间,其差距是巨大的。
这是一个由@alexwei_领导的小团队完成的成果。他把一个很少有人相信的研究想法,变成了一个几乎没人觉得可能实现的结果。当然,这一成就也离不开@OpenAI以及更广泛的AI社区多年积累的研究和工程工作。
当你在一家前沿实验室工作时,通常会提前几个月知道前沿能力在哪里。但这个结果使用了最近才开发出的新技术,甚至对许多OpenAI的研究人员来说也是一个惊喜。今天,每个人都可以看到前沿在哪里。
OpenAI的奥数题解法:https://github.com/aw31/openai-imo-2025-proofs/blob/main/problem_1.txt
相关推荐
首届AI春晚,OpenAI要边登月边修船
AI攻破高中奥数题,意味着什么?
真的要来了?5百万美元大奖激励AI斩获IMO金牌!
OpenAI震撼发布新模型,Sam Altman:耐心时刻结束了
当AI开始寻找抗生素:人类终于摘取“高悬的果实”?
多名普利策奖得主起诉OpenAI、微软:滥用自己作品训练大模型
这可能是最后一届只有人类参加的国际数学奥赛了
AI大模型的“iPhone4时刻”还要等一等
DeepSeek,中国AI的“斯普特尼克时刻”?
“编程作为一个职业在今日终结”,OpenAI新模型o1的可怕之处
网址: “AI登月时刻”,OpenAI模型摘取奥数金牌 http://www.xishuta.com/newsview139112.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



