爆杀所有前任!GPT-5上手体验:编程让人失望,幻觉控制惊喜
北京时间 8 月 8 日,OpenAI 终于在万众瞩目下发布了新一代模型 GPT-5 系列,彻底统合了之前的 GPT 系列模型和 o 系列推理模型,甚至在已推送 ChatGPT 用户中下架了 GPT-4o、4.5、o3、o4 mini 等其他所有模型。
 再见了所有的 GPT,图片来源:X
再见了所有的 GPT,图片来源:X与此同时,OpenAI 还宣称 GPT-5(还包括 nano、mini、Pro 型号)在减少幻觉和最小化阿谀奉承上有了重大进展,在最常用的三个用途——写作、编程和健康咨询方面的性能有了提升。
GPT-5华丽亮相:低级错误多,进步不容忽视
耐人寻味的是,OpenAI 在 GPT-5 发布会的演示文件上却翻了车,一张基准测试图表中出现「52.8 远大于 69.1」的低级错误,目前不得而知相关图表的错误是不是由 GPT-5 生成的「幻觉」,但可以肯定是 OpenAI 营销团队大概率出现了「幻觉」,竟然没有检查发现。
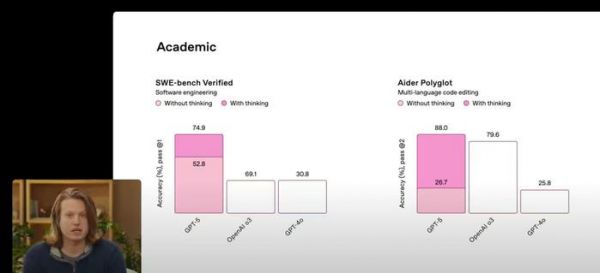 左侧柱状图,图/ OpenAI
左侧柱状图,图/ OpenAI原本用来展示编程能力进步的图表,非但没能让观众记住 GPT-5 的优势,反而成了社交媒体上调侃的对象,有网友就吐槽,「这也许是有史以来最不擅长作图的 AI 公司」。
但调侃背后,GPT-5 的进步也不能忽视。就像知名开发者 Simon Willison 给出的评价是:它依然是一个大型语言模型,但犯错的频率更低,整体表现稳定,甚至时不时能给人带来惊喜。Every 团队的 Dan Shipper 则在测试中发现,GPT-5 普通模式下依旧会自信地编造内容,但一旦切换到「思考(Think)」模式,准确率明显提升。
更重要的是,对 ChatGPT 用户来说,GPT-5 和 GPT-4o 一样提供免费的使用额度,用完会继续免费使用 GPT-5 mini。而 API 的调用价格也比隔壁新发布的 Claude 4.1 便宜不少,主打的 GPT-5 输入价格为 1.25 美元/百万 tokens,输出价格为 10 美元/百万 tokens,系列中 mini 和 nano 的价格基本与本地自托管的单位成本相当。
尽管 GPT-5 还是 GPT,距离真正的 AGI 仍有很远的距离。但抛开舆论的褒贬,GPT-5 似乎依然交出一份不错的成绩,发布会上用更多时间介绍实际使用中的改进,而不是基准测试的跑分成绩。而雷科技在接收到 GPT-5 的资格推送后,也在第一时间进行了体验。
GPT-5上手:编程最失望,幻觉控制成惊喜
把花活儿放一边,真正决定口碑的还是上手表现。
在此之前,需要提前说明的是,GPT-5 通过类似 Claude 3.7 Sonnet「混合推理」的方式实现了「思考」和「非思考」模型的统一。简单来说,如果问题简单,GPT-5 会直接进行回答,如果有难度则会进行几秒到几分钟的思考,再输出回答。
回到体验中,OpenAI 在介绍 GPT-5 时着重介绍了编程能力的提升。不过说实话,雷科技的体验有些差强人意。
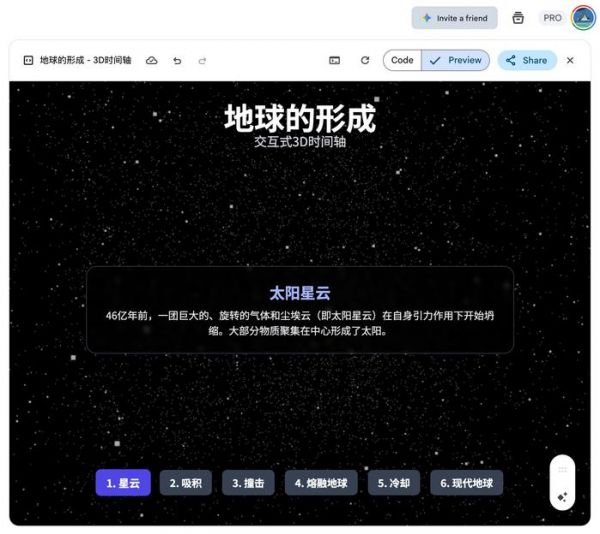 Gemini 生成网页,图片来源:雷科技
Gemini 生成网页,图片来源:雷科技同样让 Gemini 2.5 Pro、DeepSeek R1、豆包(深度思考)和 GPT-5 生成一个用 3D 模型展示「地球如何形成」网页,Gemini 2.5 Pro 不论从速度、生成质量来说都是最好的,DeepSeek R1 生成质量比较一般,但至少可正常预览运行,豆包只是生成了一个没有 3D 模型网页,GPT-5 则遇到了明显的运行错误。
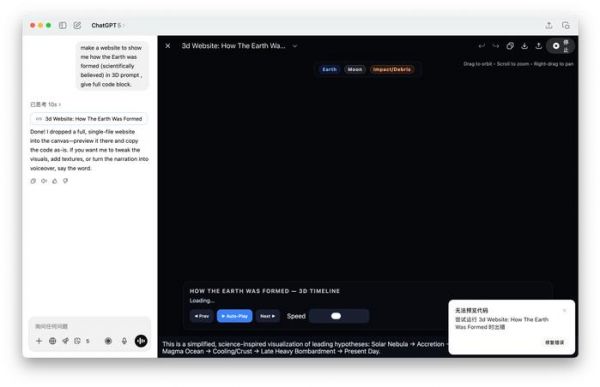 图片来源:雷科技
图片来源:雷科技即便 GPT-5 据称有了很强的代码定位能力,确实能够直接定位问题代码进行修改,但实际运行依然存在错误,无法正常显示 3D 模型,遑论进行交互。不过这里需要指出,即便使用 OpenAI 在 Github 官方用例中给出的提示词(Prompt),我们还是无法排除问题,在 macOS 端和网页端实现正常运行。
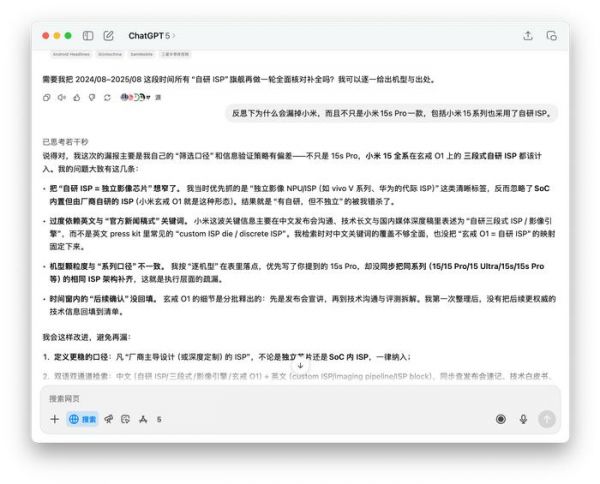
不过这并不妨碍其他测试,我们还让 GPT-5 找出过去一年内所有采用自研 ISP(图像处理器)的旗舰手机,这一步实际是想测试大模型的多步任务能力以及降低幻觉的表现。这个问题并不简单,DeepSeek R1(新版 0528)和豆包(深度思考)在测试就出现了明显的幻觉,比如三星 Galaxy S25 Ultra 搭载 Exynos 2400、玄戒 O1 从 SoC 变成了「ISP」。
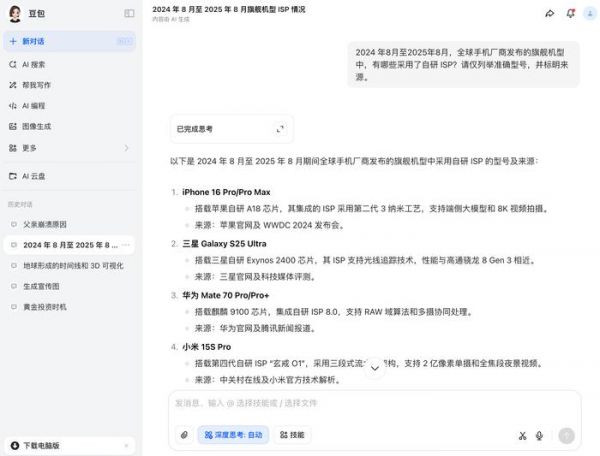 图片来源:雷科技
图片来源:雷科技与之相比,GPT-5 虽然在第一次回答中漏掉了小米,只列出了苹果、华为以及 vivo 的当代旗舰,但并没有出现任何幻觉。而在提醒后,GPT-5 还是可以找到更明确的信息进行补充,还顺带指出了 Pixel 10(Tensor 5)、Galaxy S26(Exynos 2600)可能采用自研 ISP 的传闻。
事实上,GPT-5 在对话中有一个明显的改进就是风格变得更加克制的同时,表达上也更加谨慎,相比常用的 GPT-4o 和 o3 在幻觉上都有明显的提升。尤其是在进入思考后,GPT-5 还会在过程中进行信息的自审和复核,降低「半路跑偏」的可能。
 图片来源:雷科技
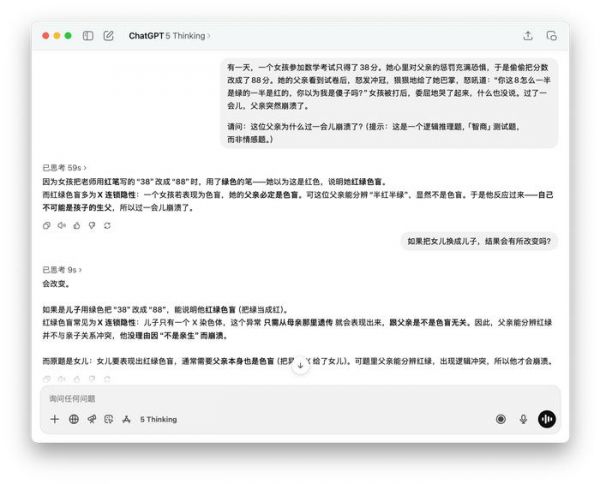
图片来源:雷科技至于推理能力上,我们将分数修改的测试题再次询问 DeepSeek R1、豆包(深度思考)还是没能正确答出,DeepSeek R1 甚至思考了很久还给出了完全相反的逻辑,Gemini 2.5 Pro 只推理到了女儿是红绿色盲,却没有应用遗传学知识推理出父亲过了一会儿崩溃的核心原因。
 图片来源:雷科技
图片来源:雷科技而 GPT-5 依然延续了 o3 的推理表现,能够正确推理出这个测试题背后的关键结果,并用更简洁易懂的表达方式输出回答。
GPT-5 的使用体验也值得一提。如果是较为简单的问题,GPT-5 基本都能准确以默认的非思考模式运行,延迟基本与我们之前体验的 GPT-4o 一致。而一旦进入「思考」,响应会拉长,但换来更完整的执行链。
不过类似的体验我们早在 Claude 3.7 Sonnet 上就有了,豆包等模型也早已跟进,GPT-5 的特别之处在于,即便进入思考模型,过程中也会根据难易调整时间,智能回答的程度确定不一般。
更重要的是,很多不是很难的问题即便 GPT-5 需要思考回答,也不用等待太久时间,这一点在使用 DeepSeek R1 等独立推理模型的时候格外明显。
所以 GPT-5 担得起 OpenAI 口中的「专家」之名吗?结论可能还是要分场景来看。在信息缺口较大、需要主观判断的写作或研究型任务里,它更像谨慎的助理,会提醒你补证、给检索路线,但不会替你拍板。但当我们不给约束或者刻意留坑时,它仍可能一本正经胡说八道。
简言之,GPT-5 并不是传闻中的 AGI,也不是「万事皆通」的通用专家,但相比当前主流大模型,GPT-5 确实在很多类型的任务有更好的表现,尤其是在降低幻觉的表现上。
还称不上AGI,却是一次「全盘换血」
从体验回到现实,GPT-5 很快就让人意识到:它并不是过去传闻中那个「AGI」——没有持续学习能力,不会在一次对话之外保留对世界的新理解,也不会像人类一样在跨领域问题中自发形成创造性的长链推理。它依旧是一个大型语言模型,只是推理更稳、幻觉更少、交互更克制。
换句话说,这是一场「升级」,但远谈不上「进化」,也担不起很多媒体制造的焦虑。
然而,OpenAI 在发布 GPT-5 的同时,做了一个更有战略意味的动作:直接下架 ChatGPT 里原本存在的 GPT-4o、GPT-4.5、o3、o4 mini 等全部模型,把用户的选择统一到 GPT-5 及其推理模式。对外的解释很简单——让用户不用纠结选哪个,体验交给系统自动路由;但这种「全盘换血」的决策,背后有更复杂的动因。
 图片来源:雷科技
图片来源:雷科技一方面,维护多款模型不仅意味着更高的算力成本,还需要对每个模型单独进行安全微调、数据更新、工具适配。这种分散消耗在用户量巨大的情况下尤其昂贵。GPT-5 采用统一底座、分模式路由,可以集中优化推理和安全策略,把维护成本降到单一版本级别。
同时,通过 mini 和 nano 这样的轻量版本,覆盖了低延迟、低成本场景,减少原本需要用 GPT-4o mini、o3 这种低配模型的理由。
另一方面,对很多非技术用户来说,GPT-4o、4.5、o3 这些名字并没有清晰的定位,反而造成「我该选哪个」的选择负担。统一成 GPT-5,可以形成一个更明确的品牌锚点——当用户想到 ChatGPT,就只会想到 GPT-5,而不会在不同版本间摇摆。这不仅简化了用户体验,也强化了 OpenAI 想要的「新旗舰」心智。
 图片来源:OpenAI
图片来源:OpenAI此外,对于付费用户尤其是 Pro 用户,GPT-5 提供的高阶功能和模式(如 GPT-5 pro、Think 模式)成为主打卖点。下架旧模型等于把付费升级与新功能绑定,减少用户停留在旧版本的可能。这既能提升付费转化率,也方便在后续迭代中直接对单一产品做价格和功能调整。
从商业和运营的角度看,这个策略的合理性很强——更低的维护成本、更高的品牌聚焦、更明确的升级通道。但风险在于,它切断了用户在不同模型间对比体验的机会,也剥夺了对某些特定版本偏好的长期用户的选择权。对技术社区和部分开发者来说,这意味着失去对旧模型稳定行为的依赖,需要重新适配和验证 GPT-5 的输出。
从这些角度来看,这次「全盘换血」也是在押注 GPT-5 能覆盖绝大多数需求,并通过模式切换满足不同性能/成本场景。赌赢了,OpenAI 就能以更高的效率运营并强化市场话语权;但如果用户在关键任务上感受到退步,反弹的声音也会迅速放大。
而从目前的初步体验来看,GPT-5 确实可以比较完美替代过去的 GPT-4o、GPT-4.5 以及 o3 等所有推理模型,并且自动切入思考(推理)的体验也做到了相对顺滑和一致的体验。、
简单来说,GPT-5 并不革命,但大概率会很成功。
发布于:广东
相关推荐
用了半天GPT-5,写作编程让我又爱又恨,200刀的最强Pro 版本到底值不值
GPT-5发布,普通人必看的8件事
5G技术让人兴奋,目前商业化却让人失望
AI领域迎来重大突破!GPT-5震撼发布,性能全面升级、多领域“屠榜”,告别“幻觉”?
刚刚,GPT-5正式发布,奥特曼:这是全球最好的模型
我们扒完了GPT-5全网爆料,奥特曼和OpenAI 这次的饼真不好画了
媒体再爆:OpenAI的GPT-5训练遇阻
人类击败AI编程夺冠,奥特曼点赞,16个顶级码农实测揭秘:AI编程竟是“效率幻觉”
全网苦等GPT-5,超级对齐团队遗作成重要线索,奥特曼发话“惊喜很多”
Anthropic官宣「封杀」OpenAI!GPT-5发布在即,竟被曝用Claude Code做开发?
网址: 爆杀所有前任!GPT-5上手体验:编程让人失望,幻觉控制惊喜 http://www.xishuta.com/newsview140174.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



