Nature封面文章: DeepSeek-R1通过强化学习激励的LLM推理
本文来自微信公众号:集智俱乐部 (ID:swarma_org),作者:JK,编辑:张倩,原文标题:《Nature封面文章: DeepSeek-R1 通过强化学习激励的LLM推理》
这篇文章的作者人数,竟然达到了将近200人,真可谓集体智慧之作。在这个长长的作者列表中,你能找到梁文锋的名字吗?

论文题目:DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
论文地址:https://www.nature.com/articles/s41586-025-09422-z
为了更好地了解本文内容,我们翻译了全文文章,并配以关键概念的说明。
摘要
通用推理一直是人工智能(AI)领域长期而艰巨的挑战。近年来,以大型语言模型(LLMs)和思维链(CoT)提示为代表的突破,在基础推理任务上取得了显著成功。然而,这种成功在很大程度上依赖于大量人工标注的示范数据,而且现有模型的能力对于更复杂的问题仍显不足。
本文表明,我们可以通过纯强化学习(RL)来激励LLM的推理能力,从而产生无需人工标注的推理轨迹。本文所提出的RL框架促进了高级推理模式的涌现式发展,例如自我反思(Self reflection)、验证以及动态策略适应。
因此,训练后的模型在数学、编程竞赛和STEM领域等可验证的任务上取得了更优的性能,超越了通过常规的基于人工示范的监督学习训练得到的同类模型。此外,这些大型模型所表现出的涌现推理模式还可以系统性地用于指导并提升小型模型的推理能力。
引言
推理能力作为人类智能的基石,使我们能够完成从数学问题求解到逻辑推断与编程等复杂的认知任务。人工智能的最新进展表明,当规模足够大时,LLM会呈现出涌现行为,其中包括推理能力。然而,在预训练阶段获得这种能力通常需要耗费大量的计算资源。
与此同时,一条互补的研究方向表明,可以通过CoT(思维链)提示有效增强LLM。该技术要么提供精心设计的少量示例,要么使用诸如“Let’s think step by step(让我们一步一步想)”这类极简提示,使模型能够生成中间推理步骤,从而显著提升其在复杂任务上的表现。同样地,在后训练阶段让模型学习高质量的多步推理轨迹时,也观察到了进一步的性能提升。
尽管这些方法行之有效,但也存在显著局限。它们对人工标注推理轨迹的依赖会降低可扩展性并引入认知偏差。此外,将模型限定为复现人类思维过程,天然会用人类提供的示例为其能力设限,从而阻碍对更优、非人类式推理路径的探索。
为解决这些问题,我们希望在强化学习(RL)框架中,通过自我进化来挖掘LLM在推理方面的潜力,并尽量减少对人工标注的依赖。具体而言,我们基于DeepSeek-V3-Base,采用组相对策略优化(Group Relative Policy Optimization,简称GRPO)作为我们的RL框架。
奖励信号仅依据最终预测与真实答案的正确性来设定,而不对推理过程本身施加任何约束。值得注意的是,我们绕过了常规的在RL训练前进行的监督微调(Supervised Fine-Tuning,简称SFT)阶段。之所以做出这一设计选择,是因为我们假设由人定义的推理模式可能会限制模型的探索;相反,不受限制的RL训练更能激励LLM涌现新的推理能力。
通过这一过程(详细内容见下一节),我们的模型(称为DeepSeek-R1-Zero)自然地发展出了多样而复杂的推理行为。为解决推理问题,模型表现出生成更长回答的倾向,并在每个回答中融入验证、自我反思以及对替代方案的探索。尽管我们并未明确教授模型如何进行推理,它仍然通过RL成功学习到了更优的推理策略。
尽管DeepSeek‑R1‑Zero展示了出色的推理能力,但它也面临一些挑战,例如可读性较差以及语言混用,偶尔会在一次CoT回答中同时出现英文和中文。此外,DeepSeek‑R1‑Zero的基于规则的强化学习训练阶段过于专注于推理任务,导致在写作和开放领域问答等更广泛领域的表现受限。
为了解决这些问题,我们提出了DeepSeek‑R1,这是一种通过多阶段学习框架训练的模型,该框架结合了拒绝采样、强化学习和监督微调,具体细节见“DeepSeek‑R1”一节。该训练流程使DeepSeek‑R1能够继承其前身DeepSeek‑R1‑Zero的推理能力,同时通过进一步的非推理数据,使模型行为与人类偏好保持一致。
为以更低的能耗让更多人能够使用强大的AI,我们蒸馏了若干更小的模型并公开发布。这些蒸馏模型表现出强大的推理能力,超过了它们最初仅做指令微调的对应版本。
我们相信,这些指令微调后的蒸馏版本也将极大地惠及科研社区,为理解长链式思维推理模型的机制、以及推动更强大推理模型的发展提供宝贵资源。我们将按照“代码可用性”一节中的说明,向公众发布DeepSeek‑R1‑Zero、DeepSeek‑R1、数据样本以及蒸馏模型。
DeepSeek‑R1‑Zero
为在大规模上实现对DeepSeek‑R1‑Zero的强化学习(RL),我们采用了高效的RL流水线。具体而言,我们使用GRPO作为我们的RL算法,详见“Methods”部分的“GRPO”。此外,我们采用基于规则的奖励系统来计算“准确性奖励”和“格式奖励”,其详细方法在“Methods”部分的“Reward design”中给出。并且,我们的高性能RL基础设施在补充材料的第2.1节中进行了描述,以确保训练具有可扩展性与高效率。
相关词条DeepSeek-R1-Zero
https://wiki.swarma.org/index.php/DeepSeek-R1-Zero
什么是GRPO?
DeepSeek-R1-Zero模型使用了一种新型的强化学习算法,即组相对策略优化算法(Group Relative Policy Optimization,简称GRPO),该算法是对经典的强化学习算法近端策略优化(Proximal Policy Optimization,PPO)的改进。二者最大的区别在于:PPO算法需要学习优化一个价值网络(Value Network)来充当评判者的决策来对生成的策略进行评估。但是,训练一个价值网络需要耗费大量内存,因此GRPO算法去掉了价值网络,并通过引入组相对奖励(Group Relative Reward)来优化策略,使得策略在组内相对表现更好,而不是仅仅依赖于绝对奖励。
为了更好地理解GRPO,我们绘制了传统的PPO算法与GRPO算法的对比图:
由该图可以清楚地看出,GRPO放弃了传统的PPO中的价值模型,转而从组分数中估计基线,显著减少了训练资源。
更具体地,我们在DeepSeek‑V3 Base上应用RL技术来训练DeepSeek‑R1‑Zero。训练期间,我们设计了一个直观的模板,要求DeepSeek‑R1‑Zero先生成推理过程,再给出最终答案。提示模板如下所示。
“一段用户与助手之间的对话。用户提出一个问题,助手来解决。助手先在脑海中思考推理过程,然后向用户给出答案。推理过程和答案分别用
...
和reasoning process here
prompt
。Assistant:”其中
prompt
会在训练时替换为具体的推理问题。我们有意将约束限制在这一结构化格式上,避免任何与内容相关的偏置,以确保我们能够准确观察到模型在RL过程中的自然演进。图1a展示了DeepSeek‑R1‑Zero在美国邀请数学考试(AIME)2024基准上的训练全过程表现效果,其中AIME 2024的平均pass@1分数显著提升,从初始的15.6%跃升至77.9%。此外,借助自一致性解码,模型性能还能进一步提升,准确率达到86.7%。这一表现大幅超过了所有AIME人类参赛者的平均水平。
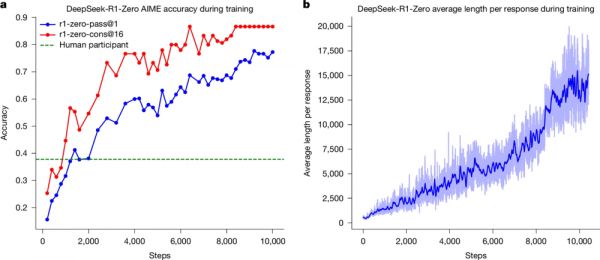
图1:DeepSeek‑R1‑Zero在整个训练过程中的准确率与输出长度。a,DeepSeek-R1‑Zero在训练过程中的AIME准确率。AIME以数学问题为输入、以数值为输出,其示例见扩展数据表1。pass@1和cons@16的说明见补充信息第4.1节。基线为AIME比赛中人类参赛者取得的平均分。b,DeepSeek-R1‑Zero在强化学习(RL)过程中于训练集上的平均回复长度。DeepSeek-R1‑Zero会自然地在更长思考时间下学习解决推理任务。注意,训练步(training step)指一次策略更新操作。
除数学竞赛外,如补充材料图8所示,DeepSeek‑R1‑Zero在编程竞赛以及研究生水平的生物、物理和化学问题上也取得了显著成绩。这些结果凸显了强化学习(RL)在提升大型语言模型(LLM)推理能力方面的有效性。
除了在训练过程中推理能力逐步增强之外,DeepSeek‑R1‑Zero还在强化学习(RL)训练中展现出自我进化的行为。如图1b所示,DeepSeek‑R1‑Zero的思考时间在整个训练中稳步增长,这完全由其内在适应性驱动,而非外部改动。借助较长的思维链(CoT),模型持续精炼其推理,在每次回答中生成数百到数千个token,以探索并改进其解决问题的策略。
思考时间的增长有助于复杂行为的自主演化。具体而言,DeepSeek‑R1‑Zero越来越多地表现出高级推理策略,如反思式推理和对替代方案的系统性探索(见扩展数据图1a),这显著提升了其在数学与编程等可验证任务上的表现。值得注意的是,在训练过程中,DeepSeek‑R1‑Zero出现了一个“灵光一现”的时刻(见表1):在反思阶段对“wait(等待)”一词的使用突然增加(见扩展数据图1b)。这一时刻标志着推理模式的显著变化,并清晰展示了DeepSeek‑R1‑Zero的自我进化过程。
DeepSeek‑R1‑Zero的自我进化凸显了强化学习(RL)的力量与魅力:与其明确教模型如何解决问题,我们只需提供合适的激励,模型便能自主发展出先进的问题求解策略。这提醒我们,RL具有释放更高层次LLM能力的潜力,为未来更自主、更具适应性的模型铺平道路。
尽管DeepSeek‑R1‑Zero展现出强大的推理能力,但它也面临若干问题。由于DeepSeek‑V3 Base在多种语言(尤其是英文和中文)上训练,DeepSeek‑R1‑Zero在可读性和语言混用方面表现欠佳。为解决这些问题,我们开发了DeepSeek‑R1,其训练流水线如图2所示。
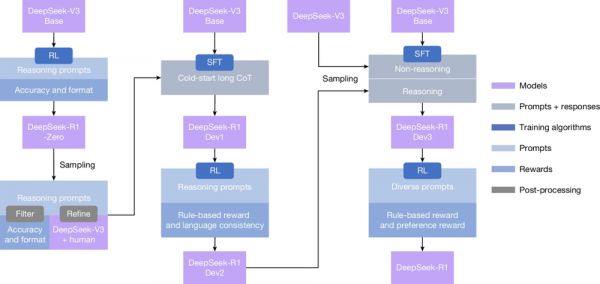
图2:DeepSeek‑R1的多阶段流水线。关于DeepSeek‑V3 Base和DeepSeek‑V3的详细背景见补充信息第1.1节。模型DeepSeek‑R1 Dev1、Dev2和Dev3表示该流水线中的中间检查点。
在初始阶段,我们收集了大量具备对话式、符合人类思维过程的冷启动数据,详细内容见补充材料第2.3.2节。
随后进行RL训练,并采用“第一阶段RL训练细节”的超参数设置;数据细节见补充材料第2.3.1节,用于提升模型在对话式思维过程与语言一致性方面的表现。
接着,我们再次应用拒绝采样并进行一次SFT(监督微调)。此阶段将推理与非推理数据集一并纳入SFT过程,详见补充材料第2.3.3节,使模型不仅能在推理任务上表现优异,也能展现出高级写作能力。
为了进一步使模型与人类偏好对齐,我们设计了第二阶段的RL,用于增强模型的有用性与无害性,同时持续打磨其推理能力。奖励细节见Methods中的“奖励设计”部分,第二阶段RL的超参数见Methods的“第二阶段RL训练细节”。
我们在以下基准上评估模型:MMLU、MMLU‑Redux、MMLU‑Pro、DROP、C‑Eval、IFEval、FRAMES、GPQA Diamond、SimpleQA、C‑SimpleQA、CLUEWSC、AlpacaEval 2.0(参考文献22)、Arena‑Hard、SWE‑bench Verified、Aider‑Polyglot、LiveCodeBench(2024‑08—2025‑01)、Codeforces、中国高中数学竞赛(CNMO 2024)以及AIME 2024(参考文献29)。这些基准的详细信息见补充表15—29。
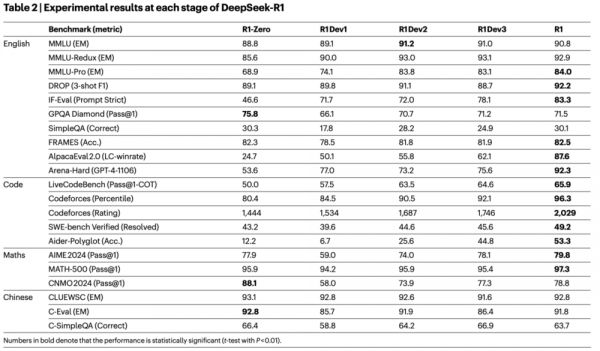
表2总结了DeepSeek‑R1在图2所示的多个开发阶段中的表现。将DeepSeek‑R1‑Zero与DeepSeek‑R1 Dev1比较,在指令跟随方面有显著提升,这在IF‑Eval和Arena‑Hard基准上的更高得分中得到体现。然而,由于冷启动数据集规模有限,Dev1的推理性能相比DeepSeek‑R1‑Zero出现一定下降,最明显的是在AIME基准上。相比之下,DeepSeek‑R1 Dev2在需要高级推理技能的基准上表现出显著提升,包括聚焦于代码生成、数学问题求解和STEM相关任务的基准。针对通用任务的基准(如AlpacaEval 2.0)仅显示出较小的改进。这些结果表明,以推理为导向的RL在影响用户偏好导向基准有限的情况下,仍能显著增强推理能力。
DeepSeek‑R1 Dev3将推理与非推理数据集共同整合进SFT流水线,从而提升模型在推理与通用语言生成任务上的熟练度。与Dev2相比,DeepSeek‑R1 Dev3在AlpacaEval 2.0和Aider‑Polyglot上取得了显著性能提升,这归因于我们引入了大规模非推理语料和代码工程类数据集。最后,在DeepSeek‑R1 Dev3上使用混合的推理聚焦数据与通用数据进行全面的RL训练,我们得到了最终的DeepSeek‑R1。由于在此前阶段已进行了大量以推理为导向的RL,模型在代码与数学基准上仅获得了小幅改进。最终版DeepSeek‑R1的主要提升体现在通用的指令跟随与用户偏好类基准上,其中AlpacaEval 2.0提升了25%,Arena‑Hard提升了17%。
我们还在补充信息第4.2节将DeepSeek‑R1与其他模型进行对比。模型安全性评估见补充信息第4.3节。全面的评估分析见补充信息第5节,其中包括与DeepSeek‑V3的比较、在新测试集上的性能评估、按类别细分的数学能力,以及测试时间缩放行为的研究。补充信息第6节显示,强大的推理能力可以迁移到更小的模型上。
相关阅读:DeepSeek-R1
https://wiki.swarma.org/index.php/DeepSeek-R1
伦理与安全声明
随着DeepSeek‑R1推理能力的提升,我们深刻意识到潜在的伦理风险。比如,R1可能遭受越狱攻击,从而生成危险内容(如爆炸物制造方案);而增强的推理能力也可能让模型给出在可操作性与可执行性上更强的规划方案。此外,公开发布的模型还容易被进一步微调,从而削弱其固有的安全防护。
在补充信息第4.3节中,我们从多个角度给出了一份全面的安全报告,包括:在开源与自建安全评测基准上的表现、跨多种语言与越狱攻击下的安全水平等。这些全面的安全分析得出结论:与其他先进模型相比,DeepSeek‑R1模型的固有安全水平总体处于中等水平(可与GPT‑4o(2024‑05‑13)相当)。此外,结合风险控制体系后,模型的安全等级可提升到更高标准。
结论、局限性与未来工作
我们提出了DeepSeek‑R1‑Zero和DeepSeek‑R1,这两者依赖于大规模强化学习(RL)来激发模型的推理行为。我们的结果表明,预训练检查点本身就对复杂推理任务具有相当大的助力。我们认为,释放这种潜力的关键不在于大规模人工标注,而在于为RL提供困难的推理问题、可靠的验证器以及充足的计算资源。在RL过程中,诸如自我校验与反思等复杂的推理行为似乎都能够自然涌现。
即使DeepSeek‑R1在推理基准上取得了前沿结果,它仍然面临若干能力上的限制,具体如下所述。
结构化输出与工具使用
目前,DeepSeek‑R1的结构化输出能力相较于现有模型仍不理想。此外,DeepSeek‑R1不能使用诸如搜索引擎与计算器等工具来提升输出效果。不过,由于为结构化输出与工具使用搭建一个RL环境并不困难,我们相信这一问题将在下个版本中得到解决。
Token效率
不同于传统的测试时计算扩展方法(如多数投票或蒙特卡罗树搜索MCTS),DeepSeek‑R1会在推理过程中根据问题的复杂度动态分配计算资源。具体而言,它在解决简单任务时使用更少的token,而在处理复杂任务时会生成更多的token。尽管如此,在token利用效率方面仍有优化空间,因为在回答较为简单的问题时,我们仍可观察到过度推理(即“overthinking”)的情况发生。
语言混用
DeepSeek‑R1目前针对中文和英文进行了优化,这在处理其他语言的查询时可能会导致语言混用的问题。比如,当查询使用英语或中文以外的语言时,DeepSeek‑R1可能会用英语进行推理并给出回答。我们计划在后续更新中解决这一限制。该限制可能与基础检查点有关:DeepSeek‑V3 Base主要使用中文和英文,因此在推理中这两种语言的表现更好。
提示工程
在评测DeepSeek‑R1时,我们发现它对提示较为敏感。少样本提示往往会降低其性能。因此,我们建议用户在零样本设置下,直接、清晰地描述问题并指定输出格式,以获得最佳结果。
软件工程任务
由于评测时间较长会影响RL流程的效率,大规模RL目前尚未在软件工程任务上得到广泛应用。因此,DeepSeek‑R1在软件工程基准上尚未显示出相对于DeepSeek‑V3的巨大提升空间。未来的版本将通过在软件工程数据上实施拒绝采样,或在RL过程中引入异步评测等方式来提升效率。
超越具体能力限制:纯RL方法本身的内在挑战:
奖励黑客(Reward hacking)
纯强化学习(RL)的成功依赖于可靠的奖励信号。本研究通过面向推理领域的基于规则的奖励模型来确保奖励的可靠性。然而,对于某些任务(如写作),这种可靠的奖励模型很难构建。如果奖励信号由模型而非预定义规则给出,随着训练推进,它更容易被“钻空子”,这意味着策略模型可能会找到捷径来“黑”掉奖励模型。因此,对于那些无法通过可靠奖励模型进行有效评估的复杂任务,单纯扩大纯RL方法的规模仍是一项开放挑战。
在本工作中,对于无法获得可靠奖励信号的任务,DeepSeek‑R1采用人工标注来构建监督数据,并仅进行数百步的RL。我们希望未来能够获得更鲁棒的奖励模型,以解决此类问题。
随着像DeepSeek‑R1这样的纯RL方法的出现,未来在解决任何能被验证器有效评估的问题方面都蕴含巨大潜力,而不论其对人类而言有多复杂。配备此类先进RL技术的机器,有望在这些领域超越人类能力,其动力源于它们通过试错迭代来优化性能的能力。然而,对于那些难以构建可靠奖励模型的任务,仍然存在挑战。在这类情形下,缺乏稳健的反馈机制可能会减缓进展,这表明未来研究应致力于开发创新方法,以便为这些复杂、难以验证的问题定义并完善奖励结构。
此外,在推理过程中使用工具也展现出显著前景。无论是使用编译器或搜索引擎来检索或计算必要信息,还是在现实世界中使用生物或化学试剂来验证最终结果,这种工具增强型推理的融合都可能极大拓展机器驱动解决方案的适用范围与准确性。
相关阅读:DeepSeek R1
方法
GRPO
GRPO是我们用于训练DeepSeek‑R1‑Zero和DeepSeek‑R1的强化学习(RL)算法。它最初被提出是为了简化训练流程并降低近端策略优化(PPO)的资源消耗,该方法在大语言模型的RL阶段被广泛采用。GRPO的流程展示于扩展数据图2中。
对于每个问题(q),GRPO会从旧策略中采样一组输出o1,o2,…,oG,随后通过最大化以下目标来优化策略模型(πθ)。
其中,(πref)是参考策略,ϵ和β为超参数,Ai是优势项(advantage),其通过每组对应于各个输出的奖励r1,r2,…,rG)计算得到:
我们在补充信息第1.3节中给出了GRPO与PPO的对比。
奖励设计
奖励是训练信号的来源,决定了强化学习(RL)优化的方向。对于DeepSeek‑R1‑Zero,我们使用基于规则的奖励,为数学、编程与逻辑推理等领域的数据提供精确反馈。对于DeepSeek‑R1,我们在此基础上进一步扩展:对推理类数据采用基于规则的奖励,对通用数据采用基于模型的奖励,从而提升学习过程在不同领域间的适应性。
基于规则的奖励
我们的基于规则的奖励系统主要包含两类奖励:准确性奖励与格式奖励。
准确性奖励:评估回答是否正确。比如,对于具有确定性结果的数学题,要求模型按指定格式(例如在方框内)给出最终答案,以便进行可靠的基于规则的正确性校验。类似地,对于编程竞赛类提示词,可使用编译器依据一套预定义测试用例来评估模型的输出,从而对正确性生成客观反馈。
格式奖励:用特定的格式要求来补充准确性奖励机制。具体而言,模型被激励将其推理过程封装在指定标签内,特别是使用
和。这样可以使模型的思考过程被清晰地呈现,增强可解释性,并便于后续分析。基于模型的奖励与权重设置
我们将准确性奖励与格式奖励以相同权重进行组合。值得注意的是,我们避免在推理任务中使用神经奖励模型——无论是基于结果的还是基于过程的。做出这一决定的依据是我们观察到:在大规模RL中,神经奖励模型容易受到“奖励黑客”的影响。此外,重新训练这类模型需要大量计算资源,并会给训练流水线引入更多复杂性,从而使整体优化过程更加复杂。
基于模型的奖励
对于通用数据,我们采用奖励模型来捕捉人类在复杂且细微场景中的偏好。我们在DeepSeek‑V3的流水线上构建,并使用类似的偏好对与训练提示的分布。
针对“有用性(helpfulness)”,我们只关注最终总结,确保评估强调回答对用户的用途与相关性,同时尽量减少对底层推理过程的干扰。
针对“无害性(harmlessness)”,我们会评估模型的完整响应,包括推理过程与总结,以识别并缓解在生成过程中可能出现的任何潜在风险、偏见或有害内容。
有用性奖励模型(Helpful reward model)
为了训练有用性奖励模型,我们首先使用DeepSeek‑V3依据Arena‑Hard提示格式(见补充信息第2.2节)生成偏好对。每个偏好对由一个用户问题和两个候选答案组成。对于每个偏好对,我们向DeepSeek‑V3询问四次,并将回答随机指定为“回答A”或“回答B”,以减少位置偏差。最终的偏好分数由这四次独立判断的平均值确定,仅保留分差Δ大于1的配对,以确保差异具有意义。
此外,为了最小化与长度相关的偏差,我们确保整个数据集中被选中和被拒绝的回答在长度上大体相当。总体而言,我们精选了66,000对数据用于训练奖励模型。该数据集中的提示均为非推理问题,来源于公开的开源数据集,或来自明确同意共享其数据以用于模型改进的用户。
我们的奖励模型架构与DeepSeek‑R1一致,并在此基础上增加了一个用于预测标量偏好分数的奖励头(reward head)。
有用性奖励模型在整个训练数据集上以单轮(epoch)方式训练,批大小为256,学习率为6×10-6。训练期间的最大序列长度设为8192个token,而在奖励模型推理阶段不施加明确的长度限制。
安全性奖励模型
为评估并提升模型安全性,我们整理了一个包含106,000个提示的数据集,这些提示配有模型生成的回答,并依据预定义的安全指南被标注为“安全”或“不安全”。与有用性奖励模型中使用的成对损失(pairwise loss)不同,安全性奖励模型使用点式方法(pointwise methodology)来区分安全与不安全的回答。其训练超参数与有用性奖励模型相同。
对于通用查询,每个样本都会被归入安全数据集或有用性数据集之一。分配给每个查询的通用奖励Rewardgeneral与其所属数据集中定义的相应奖励一致。
训练细节
DeepSeek‑R1‑Zero的训练细节
为了训练DeepSeek‑R1‑Zero,我们将学习率设为(3×10-6),将KL(Kullback–Leibler)系数设为0.001,采样温度在rollout时设为1。对于每个问题,我们采样16个输出:在8.2k步之前的最大长度为32,768个token,在8.2k步之后最大长度为65,536个token。
由此,DeepSeek‑R1‑Zero的性能与响应长度在第8.2k步出现显著跃升;训练总计进行到10,400步,对应约1.6个训练epoch。每个训练步包含32个不同的问题,因此每步的训练批大小为512。每400步,我们用最新的策略模型替换参考模型。为加速训练,每次rollout产生8,192个输出,随机划分为16个小批次,仅训练一个内部epoch。
第一阶段RL的训练细节
在RL的第一阶段,我们将学习率设为3×10-6,KL系数为0.001,GRPO的裁剪比率(ϵ)设为10,rollout的采样温度为1。对于每个问题,我们采样16个输出,最大长度为32,768个token。每个训练步包含32个不同的问题,因此每步的训练批大小为512。每400步,我们用最新的策略模型替换参考模型。为加速训练,每次rollout产生8,192个输出,随机划分为16个小批次,仅训练一个内部epoch。另一方面,为了减轻在RL训练期间语言混用的问题,我们引入了语言一致性奖励,其计算方式是根据在CoT中目标语言词语所占的比例。
第二阶段RL训练细节与语言一致性奖励
虽然补充材料第2.6节中的消融实验显示,这种对齐会使模型性能略有下降,但该奖励符合人类偏好,使文本更易读。我们将语言一致性奖励直接加到最终奖励中,同时应用于推理类与非推理类数据。
请注意,裁剪比率(clip ratio)在训练中起着关键作用。数值较低会导致大量token的梯度被截断,从而降低模型性能;而数值较高则可能在训练中引发不稳定性。本阶段所用RL数据的细节见补充材料第2.3节。
第二阶段RL的训练细节
具体而言,我们使用奖励信号与多样化提示分布的组合来训练模型。对于推理数据,我们遵循DeepSeek‑R1‑Zero中描述的方法,使用基于规则的奖励来引导数学、编程与逻辑推理等领域的学习。在训练过程中我们观察到,当RL提示涉及多种语言时,CoT常会出现语言混用。对于通用数据,我们使用奖励模型来引导训练。最终,融合多种奖励信号与多样的数据分布,使我们能够得到一个不仅在推理上表现出色、同时也优先考虑有用性与无害性的模型。
给定一批数据,奖励可表述为:
第二阶段的RL基本沿用了第一阶段的大多数参数,主要区别是将温度降低到0.7,因为我们发现在该阶段使用更高温度会导致生成结果不连贯。该阶段共包含1,700个训练步,其中通用指令数据与基于偏好的奖励仅在最后400个训练步中引入。我们发现,使用基于模型的偏好奖励信号进行更多训练步可能会导致“奖励黑客”现象,相关内容记录于补充材料第2.5节。
数据可用性(Data availability)
我们在以下链接提供了用于拒绝采样与RL提示的数据样本:https://github.com/deepseek-ai/DeepSeek-R1(https://doi.org/10.5281/zenodo.15753193)。关于我们完整数据生成方法的综合统计与细节,见补充材料第2.3节。
代码可用性(Code availability)
在MIT许可证下,DeepSeek‑R1‑Zero与DeepSeek‑R1的训练权重可在此获取:https://github.com/deepseek-ai/DeepSeek-R1(https://doi.org/10.5281/zenodo.15753193)。推理脚本发布于:https://github.com/deepseek-ai/DeepSeek-V3(https://doi.org/10.5281/zenodo.15753347)。
神经网络使用PyTorch开发,分布式框架基于我们内部的HAI‑LLM框架(https://www.high-flyer.cn/en/blog/hai-llm)。推理框架基于vLLM。
数据分析使用Python v3.8(https://www.python.org/)、NumPy v.1.23.1(https://github.com/numpy/numpy)、Matplotlib v.3.5.2(https://github.com/matplotlib/matplotlib)以及TensorBoard v.2.9.1(https://github.com/tensorflow/tensorboard)。
参考文献
1.Brown,T.B.et al.Language models are few-shot learners.In Advances in Neural Information Processing Systems 33(eds Larochelle,H.et al.)(ACM,2020).
2.OpenAl etal.GPT4 technical report.Preprint at https://doi.org/10.48550/arXiv.2303.08774(2024).
3.Wei,J.et al.Chain-of-thought prompting elicits reasoning in large language models.In Advancesin Neural Information Processing Systems 35(eds Koyejo,S.et al.)24824-24837(ACM,2022).
5.Kaplan,J.et al.Scaling laws for neural language models.Preprint at https://doi.org/10.48550/arXiv.2001.08361(2020).
6.Kojima,T.,Gu,S.S.,Reid,M.,Matsuo,Y.&Iwasawa,Y.Large language models are zero-shot reasoners.In Advances in Neural Information Processing Systems 35(eds Oh,A.H.et al.)22199–22213(ACM,2022).
7.Chung,H.W.et al.Scaling instruction-finetuned language models.J.Mach.Learn.Res.25,1–53(2024).
8.DeepSeek-AI et al.DeepSeek-V3 technical report.Preprint at https://doi.org/10.48550/arXiv.2412.19437(2025).
9.Shao,Z.et al.DeepSeekMath:pushing the limits of mathematical reasoning in open language models.Preprint at https://doi.org/10.48550/arXiv.2402.03300(2024).
10.Wang,X.et al.Self-consistency improves chain of thought reasoning in language models.In 11th International Conference on Learning Representations(ICLR,2023).
11.Hendrycks,D.et al.Measuring massive multitask language understanding.In 9th International Conference on Learning Representations(ICLR,2021).
12.Gema,A.P.et al.Are we done with MMLU?In Proc.2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics:Human Language Technologies(eds Chiruzzo,L.et al.)Vol.1(Long Papers),5069–5096(ACL,2025).
13.Wang,Y.et al.MMLU-Pro:a more robust and challenging multi-task language understanding benchmark.In Advances in Neural Information Processing Systems 37(eds Globersons,A.et al.)95266–95290(ACM,2024).
14.Dua,D.et al.DROP:a reading comprehension benchmark requiring discrete reasoning over paragraphs.In Proc.2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies Vol.1(Long and Short Papers)(eds Burstein,J.et al.)2368–2378(ACL,2019).
15.Huang,Y.et al.C-EVAL:a multi-level multi-discipline Chinese evaluation suite for foundation models.In Advances in Neural Information Processing Systems 36(eds Oh,A.et al.)62991–63010(ACM,2023).
16.Zhou,J.et al.Instruction-following evaluation for large language models.Preprint at https://doi.org/10.48550/arXiv.2311.07911(2023).
17.Krishna,S.et al.Fact,fetch,and reason:a unified evaluation of retrieval-augmented generation.In Proc.2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics:Human Language Technologies Vol.1(Long Papers)4745–4759(ACL,2025).
18.Rein,D.et al.GPQA:a graduate-level Google-proof Q&A benchmark.Preprint at https://doi.org/10.48550/arXiv.2311.12022(2023).
19.OpenAI.Introducing SimpleQA;https://openai.com/index/introducing-simpleqa/(2024).
20.He,Y.et al.Chinese SimpleQA:a Chinese factuality evaluation for large language models.In Proc.63rd Annual Meeting of the Association for Computational LinguisticsVol.1(Long Papers),19182–19208(ACL,2025).
21.Xu,L.et al.CLUE:a Chinese Language Understanding Evaluation benchmark.In Proc.28th International Conference on Computational Linguistics(eds Scott,D.et al.)4762–4772(International Committee on Computational Linguistics,2020).
22.Dubois,Y.,Galambosi,B.,Liang,P.&Hashimoto,T.B.Length-controlled AlpacaEval:a simple way to debias automatic evaluators.Preprint at https://doi.org/10.48550/arXiv.2404.04475(2025).
23.Li,T.et al.From crowdsourced data to high-quality benchmarks:Arena-Hard and BenchBuilder pipeline.Preprint at https://doi.org/10.48550/arXiv.2406.11939(2024).
24.OpenAI.Introducing SWE-bench verified;https://openai.com/index/introducing-swebench-verified/(2024).
25.Aider.Aider LLM leaderboards;https://aider.chat/docs/leaderboards/(2024).
26.Jain,N.et al.LiveCodeBench:holistic and contamination free evaluation of large
language models for code.In 13th International Conference on Learning Representations(ICLR,2024).
27.Mirzayanov,M.Codeforces;https://codeforces.com/(2025).
28.Chinese Mathematical Society(CMS).Chinese National High School Mathematics Olympiad;https://www.cms.org.cn/Home/comp/comp/cid/12.html(2024).
29.Mathematical Association of America.American Invitational Mathematics Examination;
https://maa.org/maa-invitational-competitions(2024).
30.OpenAI.Hello GPT-4o;https://openai.com/index/hello-gpt-4o/(2024).
31.Schulman,J.,Wolski,F.,Dhariwal,P.,Radford,A.&Klimov,O.Proximal policy optimizationalgorithms.Preprint at https://doi.org/10.48550/arXiv.1707.06347(2017).
32.Ouyang,L.et al.Training language models to follow instructions with human feedback.In Advances in Neural Information Processing Systems 35(eds Koyejo,S.et al.)27730–27744(ACM,2022).
33.Nano et al.deepseek-ai/DeepSeek-R1:v1.0.0.Zenodo https://doi.org/10.5281/zenodo.15753192(2025).
34.Yu,X.et al.deepseek-ai/DeepSeek-V3:v1.0.0.Zenodo https://doi.org/10.5281/zenodo.15753346(2025).
35.Paszke,A.et al.PyTorch:an imperative style,high-performance deep learning library.In Advances in Neural Information Processing Systems 32(eds Wallach,H.M.et al.)8026–8037(ACM,2019).
36.Kwon,W.et al.Efficient memory management for large language model serving with PagedAttention.In Proc.ACM SIGOPS 29th Symposium on Operating Systems Principles611–626(ACM,2023).
参考文献可上下滑动查看
大模型2.0读书会
o1模型代表大语言模型融合学习与推理的新范式。集智俱乐部联合北京师范大学系统科学学院教授张江、Google DeepMind研究科学家冯熙栋、阿里巴巴强化学习研究员王维埙和中科院信工所张杰共同发起「大模型II:融合学习与推理的大模型新范式」读书会,本次读书会将关注大模型推理范式的演进、基于搜索与蒙特卡洛树的推理优化、基于强化学习的大模型优化、思维链方法与内化机制、自我改进与推理验证。希望通过读书会探索o1具体实现的技术路径,帮助我们更好的理解机器推理和人工智能的本质。读书会已完结,现在报名可加入社群并解锁回放视频权限。
详情请见:大模型2.0读书会:融合学习与推理的大模型新范式!
相关推荐
强化学习,正在引领AI跨越LLM之谷
OpenAI:LLM能感知自己在被测试,为了通过会隐藏信息欺骗人类
DeepSeek-R1超高幻觉率解析:为何大模型总“胡说八道”?
Nature封面:人类又输给了AI,这次是玩《GT赛车》游戏
为何强化学习火遍硅谷?AGI的关键一步
18万引大牛Sergey Levine:不是视频模型“学习”慢,而是LLM走捷径
如何优化测试时计算?解决「元强化学习」问题
迈向人工智能的认识论:真的没有人真正了解大型语言模型 (LLM) 的黑箱运作方式吗
Nature封面重磅:社交网络影响集体决策,或改变选举结果
马斯克发布Grok 3,推理能力超o3和DeepSeek-R1
网址: Nature封面文章: DeepSeek-R1通过强化学习激励的LLM推理 http://www.xishuta.com/newsview141979.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



