清华大学集成电路学院副院长唐建石:高算力芯片,如何突破瓶颈?
来源:半导体产业纵横

存算一体+ 芯粒技术,清华团队开辟高算力新路径。

2025 年9月24日,清华大学集成电路学院副院长、长聘副教授唐建石在2025 IC WORLD 高峰论坛上,发表题为《高算力芯片发展路径探索与存算一体芯片》的演讲。演讲围绕学院近年在高算力芯片与存算一体芯片领域的思考、探索及实践展开,系统阐述了行业现状、技术突破与未来规划。
从他的演讲中,我们获取了以下关键信息:
AI 时代算力需求爆发,硬件面临双重挑战
芯片算力三要素:晶体管集成密度× 芯片面积 × 单个晶体管算力
聚焦忆阻器技术,实现存算一体芯片突破与产业化
唐建石指出,当前人工智能领域对算力的需求呈爆发式增长,国家计算力指数与数字经济、GDP 增长紧密相关。其中,中国智能算力规模 2025 年已突破数十万亿亿次,且 AI 算力需求每不到六个月便实现翻倍,这一增速远超摩尔定律驱动的硬件算力提升速度,构建更强力的芯片算力底座成为行业迫切需求。
同时,计算芯片与存储芯片存在显著差异:存储芯片拥有统一的标准接口与定义,而计算芯片需依赖指令集、工具链、操作系统构成的完整生态支撑。从行业格局看,美国长期主导计算芯片体系,我国则面临双重硬件制约:一是摩尔定律逐步放缓,晶体管尺寸微缩难度加大,叠加EUV 光刻机禁运影响,先进制造工艺推进受阻;二是先进光刻机单次曝光尺寸固定为 858 平方毫米,限制了 GPU 等单芯片的最大面积,两者共同制约了单芯片晶体管数量的提升。
为突破现有瓶颈,唐建石团队将芯片算力拆解为“晶体管集成密度 × 芯片面积 × 单个晶体管算力” 三个核心要素,针对每个要素展开技术探索。
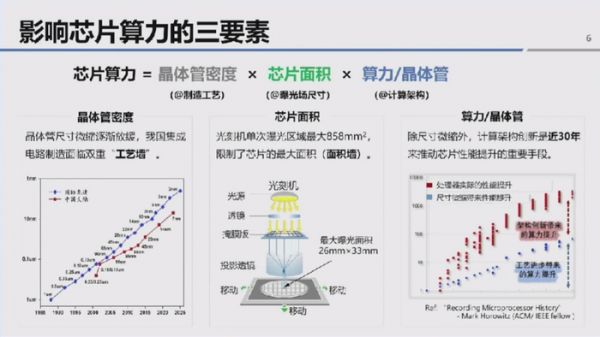
传统提升集成密度的路径依赖晶体管尺寸微缩,当前已实现每平方毫米数亿个晶体管的集成(如英伟达H200 GPU 在 800 平方毫米面积内集成近 1000 亿个晶体管),但同时面临功耗、成本与良率的挑战。唐建石表示,未来要实现超万亿晶体管的集成目标,需依托以芯粒技术为代表的 2.5D/3D 集成技术,通过多芯片垂直堆叠将集成维度从 “面密度” 拓展至 “体密度”。
芯粒技术是融合架构设计、互联设计、存储封装、电源散热及先进光刻的综合技术体系。为推进自主生态建设,学院联合国内优势单位采取“一加一” 模式:一方面牵头组建 “中国中关村高性能芯片互联技术联盟”,已制定 12 项团体标准、牵头编制 5 项国家标准,构建我国芯粒技术自主标准框架;另一方面依托国家重大项目建设 “北京芯力技术创新中心”,打造芯粒技术一站式服务平台,目前该平台已完成通线并初步具备小批量量产能力。
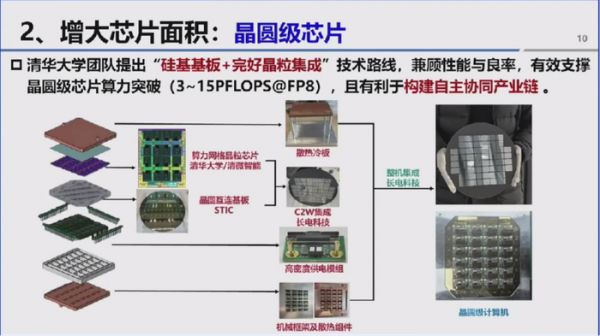
针对光刻机曝光尺寸的限制,行业主流方向是研发“晶圆级芯片(One Chip One Die)”,唐建石介绍了国际上两类典型技术路线:一是 19 年Cerebras WSE推出的,采用曝光厂拼接技术将12 寸晶圆制成完整芯片,但需通过小计算核设计与容错架构保障良率;二是 Tesla Dojo 路线,采用完好晶粒结合有机基板重塑12 寸晶圆,但其有机基板无法实现 DTC 功能,电气特性较弱且互联带宽低,需大量架构优化,落地难度逐步增加。
学院团队提出“硅基基板 + 完好晶粒” 的技术路线,可同时兼顾芯片性能与良率,经测试能支撑芯片算力达到 3-15 PFlops@FP8 ,性能超过4 纳米工艺的英伟达GB200 GPU。
在存算一体技术的具体探索中,唐建石重点介绍了团队在忆阻器领域的研究成果,涵盖技术优势、工艺突破、创新方案及产业化进展:
忆阻器采用“两电极 + 中间氧化层组变层” 的简单结构,通过施加电源脉冲调节电导可实现多比特非易失存储。将忆阻器制成交叉阵列后,可将矩阵值映射为电导值、向量作为电压输入,依托欧姆定律与基尔霍夫定律完成矩阵向量乘加运算 —— 单个忆阻器可同时承担多比特乘法器、加法器与存储单元的功能。
相比传统数字电路,忆阻器的能效比CPU、GPU 提升一个数量级,且在擦写速度、耐久性、多比特存储能力及成本方面,均优于闪存、MRAM、PCM 等其他非易失存储器。过去十年,忆阻器存算一体技术从器件材料优化、交叉阵列功能演示,逐步发展到 2018 年后与 CMOS 电路集成打造原型芯片,呈现指数级发展趋势。
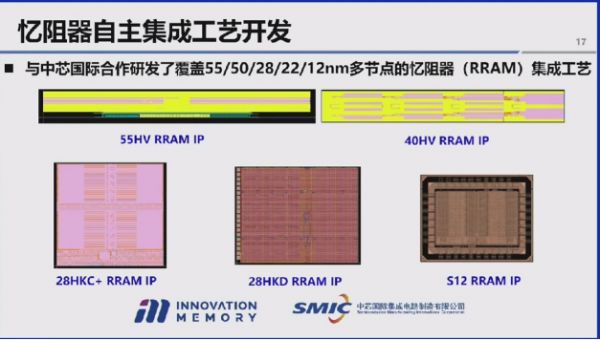
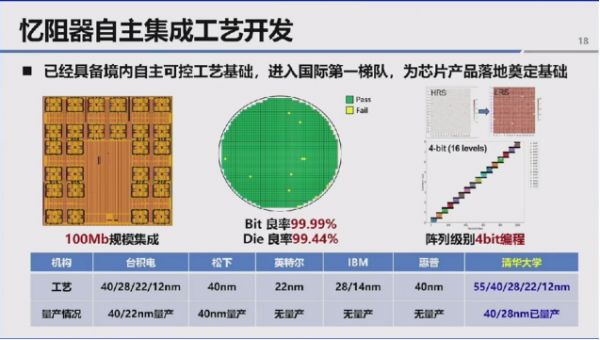
过去四年多,团队与中芯国际合作研发出覆盖55 纳米、40 纳米、28 纳米、22 纳米至 12 纳米多个节点的忆阻器集成工艺。由于忆阻器集成于CMOS 后道,具备良好的工艺迁移能力,可适配更先进的工艺节点。目前团队已形成境内自主可控的工艺基础,忆阻器集成规模达上百兆,良率可达 4 个 9 至 6 个 9,实现 4 比特编程,且 40 纳米、28 纳米节点的存储产品已实现一定规模量产,工艺水平进入国际第一梯队。
针对忆阻器存算一体的核心技术痛点,团队提出两项关键创新方案:一是为提升计算精度,研发“混合训练架构”,提取器件与阵列的非理想特性及噪声特性建模后,融入神经网络离线训练过程,权重映射至芯片后,通过关键层的片上自适应调节实现精度优化,据此研制出国际首款多阵列忆阻器存算一体系统,成功演示多层卷积神经网络计算,能效达 110+ TOPS/W;二是为实现片上训练,针对忆阻器 “写操作难度高、功耗与时间开销大、耐擦写次数有限” 的特性,提出 “Stellar 片上学习框架”,大幅减少权重更新次数与能耗,研制出国际首款全系统集成的支持片上高效学习的忆阻器双算力芯片,在相同任务下,能耗比先进工艺数字芯片低 1-2 个数量级,验证了忆阻器芯片同时支持神经网络推理与片上训练的能力。


在产业化推进方面,忆阻器存储技术已相对成熟,台积电也在推进 12 纳米及更先进节点的忆阻器存储工艺研发。团队孵化的企业已实现 1-16MB 典型规格忆阻器存储产品的量产。在存算一体领域,团队孵化 “北京亿元科技” 初创公司,既推出面向科研的存算一体硬件平台,与多所高校开展合作,也联合咪咕、字节跳动研发存算一体计算加速卡,在内容推荐场景开展探索性应用。
唐建石在演讲结尾总结,当前我国先进制造工艺面临制约,实现高算力芯片突破需依托多层次协同创新:一方面引入存算一体新计算范式,推动其与进程计算、主流计算架构的融合,突破算力、存储与功耗瓶颈;另一方面通过芯粒堆叠、单片三维集成等技术,构建异构集成层次化芯片,突破单芯片面积限制。
他表示,通过计算范式、芯片架构与集成方法的协同创新,可构建异构集成、存算融合的智能计算架构,为后摩尔时代算力提升开拓新空间。此外,团队正关注硅光、光电子融合等技术,计划引入光模块加速数据传输,丰富高效芯片的技术探索路径。
相关推荐
清华大学集成电路学院副院长唐建石:高算力芯片,如何突破瓶颈?
最前线|清华大学成立集成电路学院,解决芯片人才荒
重磅!清华大学成立人工智能学院
不做大模型的AI芯片,清华大学“ACCEL”有何不同?
刚刚,清大团队研发3000倍超高速光电芯片,这将是一场惊人的算力革命!
全球首颗!我国芯片领域取得重大突破
刚刚,清华集成电路学院成立,校友占比半导体产业半壁江山,现在瞄准“中国芯”
中国造超高速芯片 算力是现在芯片的3000倍
扎堆了!北大、华中科大重磅成立芯片学院,加上清华平均一个月一家
36氪首发|「清微智能」获数亿元B轮融资,普罗资本旗下国开装备基金领投
网址: 清华大学集成电路学院副院长唐建石:高算力芯片,如何突破瓶颈? http://www.xishuta.com/newsview142674.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



