DeepSeek开源新模型
(文/陈济深 编辑/张广凯)
10月20日,DeepSeek再度开源新模型。
在GitHub(https://github.com/deepseek-ai/DeepSeek-OCR)上可以看到其最新模型名为DeepSeek-OCR,还是一款OCR(光学字符识别)模型,该模型的参数量为3B。
该项目由 DeepSeek 三位研究员 Haoran Wei、Yaofeng Sun、Yukun Li 共同完成。其中一作 Haoran Wei 曾在阶跃星辰工作过,曾主导开发了旨在实现「第二代 OCR」的 GOT-OCR2.0 系统(arXiv:2409.01704),该项目已在 GitHub 收获了超 7800 star。也因此,由其主导 DeepSeek 的 OCR 项目也在情理之中。

DeepSeek 表示,DeepSeek-OCR 模型是通过光学二维映射(将文本内容压缩到视觉像素中)来高效压缩长文本上下文。
该模型主要由 DeepEncoder 和 DeepSeek3B-MoE-A570M 解码器两大核心组件构成。其中 DeepEncoder 作为核心引擎,既能保持高分辨率输入下的低激活状态,又能实现高压缩比,从而生成数量适中的视觉 token。
实验数据显示,当文本 token 数量在视觉 token 的 10 倍以内(即压缩率
这一结果显示出该方法在长上下文压缩和 LLM 的记忆遗忘机制等研究方向上具有相当潜力。
此外,DeepSeek-OCR 还展现出很高的实用价值。在 OmniDocBench 基准测试中,它仅使用 100 个视觉 token 就超过了 GOT-OCR2.0(每页 256 个 token) 的表现;同时,使用不到 800 个视觉 token 就优于 MinerU2.0(平均每页超过 6000 个 token)。在实际生产环境中,单张 A100-40G GPU 每天可生成超过 20 万页(200k+) 的 LLM/VLM 训练数据。
DeepSeek 探索的方法概括起来就是:利用视觉模态作为文本信息的高效压缩媒介。
简而言之,一张包含文档文本的图像可以用比等效文本少得多的 Token 来表示丰富的信息,这表明:通过视觉 Token 进行光学压缩可以实现高得多的压缩率。
基于这一洞见,DeepSeek 从以 LLM 为中心的视角重新审视了视觉语言模型 (VLM),其中,他们的研究重点是:视觉编码器如何提升 LLM 处理文本信息的效率,而非人类已擅长的基本视觉问答 (VQA) 任务。DeepSeek 表示,OCR 任务作为连接视觉和语言的中间模态,为这种视觉 - 文本压缩范式提供了理想的试验平台,因为它在视觉和文本表示之间建立了自然的压缩 - 解压缩映射,同时提供了可量化的评估指标。
鉴于此,DeepSeek-OCR 便由此而生。这是一个为实现高效视觉 - 文本压缩而设计的 VLM。
如图所示,DeepSeek-OCR 采用了一个统一的端到端 VLM 架构,由一个编码器和一个解码器组成。
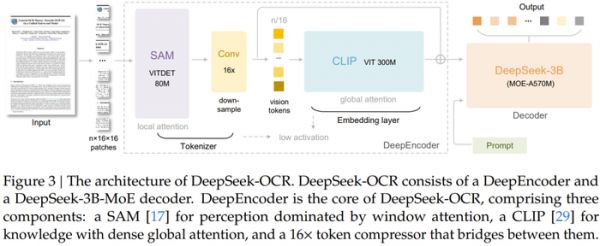
DeepSeek-OCR 的创新架构不仅实现了高效的视觉-文本压缩,更在实际应用中展现出强大的性能潜力。
这一模型的核心突破在于其独特的双组件设计:DeepEncoder编码器和MoE解码器。
在编码器层面,DeepSeek创造性地将SAM-base的局部感知能力与CLIP-large的全局理解优势相结合。就像一位经验丰富的古籍修复师,它既能用"显微镜"精准识别每个字符的细节(窗口注意力),又能用"广角镜"把握整篇文档的版式结构(全局注意力)。特别值得注意的是其创新的16倍下采样机制——这相当于将一本300页的书籍压缩到20页的体量,却仍能保留97%的关键信息。
而MoE解码器采用的混合专家机制犹如一个专业翻译团队:面对不同语种、不同版式的文档时,系统会自动激活最擅长的6位"专家"协同工作。这种动态资源调配使得3B参数的大模型在实际运行时仅需570M参数的计算开销,在A100显卡上就能实现每天20万页的处理效率——相当于100名专业录入员的工作量。
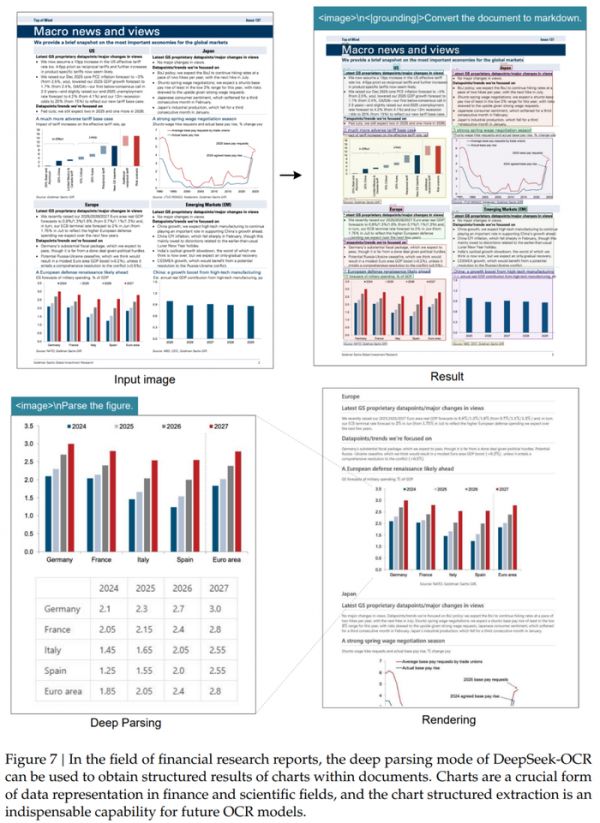
在实际测试中,DeepSeek-OCR 展现了惊人的适应性:
对于简单的PPT文档,仅需64个视觉token就能准确还原内容,识别速度堪比人类扫视;
处理复杂的学术论文时,400个token即可完整保留数学公式、化学方程式等专业符号;
在多语言混合文档测试中,模型成功识别出阿拉伯语与僧伽罗语等特殊文字;
此外,DeepSeek-OCR 还具备一定程度的通用图像理解能力。

这也意味着DeepSeek-OCR存在广泛应用潜力,在金融领域,它可以将厚厚的财报瞬间转为结构化数据;在医疗行业,能快速数字化历史病历档案;对出版机构而言,古籍数字化效率将提升数十倍。更值得关注的是,该模型展现出的"视觉记忆"特性,为突破大语言模型的上下文长度限制提供了全新思路。
发布于:上海
相关推荐
DeepSeek开源新模型
DeepSeek开源新模型,数学推理能力大提升
方舟健客全面接入deepseek开源大模型,引领互联网医疗新变革
DeepSeek等开源模型,更“浪费”token吗?
DeepSeek促AI开源浪潮涌动
DeepSeek再发新模型
DeepSeek开源周:开源可能是不想赚钱,也可能是想推动更大变化
DeepSeek大模型专家交流
奥特曼称DeepSeek并未影响GPT增长,将推更好的开源模型
DeepSeek新发布
网址: DeepSeek开源新模型 http://www.xishuta.com/newsview143435.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



