还在卷长文本?谷歌直接把文本干到无限长了
当人们还在比拼上下文窗口的时候,谷歌发布了这样一篇论文《Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention》。论文中写到,团队发明了一种新的注意力技术,叫做“无限注意力”(Infini-attention),通过这项技术,能使Transformer大模型在有限的计算资源条件下,处理无限长度的输入。
在一个transformer模型中,注意力的作用是允许模型根据当前位置的输入元素(如词元或token)来分配权重给序列中其他所有位置的元素。而上下文窗口则限制了注意力机制的实际操作范围,即模型在计算注意力时仅考虑当前元素周围特定范围内(前后若干位置)的其他元素。
无限注意力允许允许模型在处理无限长输入序列的时候,仍能保持对上下文信息的访问能力,再也不需要在处理新输入时丢弃前一输入段的注意力状态了。那么也就是说,它的上下文窗口可以是……无限。
无限注意力机制背后的关键技术叫做压缩记忆系统,这是一种能够以紧凑形式存储和检索大量信息的结构,通过改变自身参数来捕获新信息,确保信息可以在之后被恢复。单从运行的逻辑上来讲,压缩记忆系统和咱们日常生活里压缩文件是一模一样的。
压缩记忆系统最大的作用是克服transformer标准注意力机制在处理长序列时存在的内存足迹和计算时间的二次复杂度问题,只需要通过使用固定数量的参数存储和召回信息,确保存储和计算成本保持在可控范围内。因为其参数数量不随输入序列的增长而变化,那也就是说,无论输入序列长度有多长,也不会对影响模型的复杂度。
接下来无限注意力机制会将输入序列划分为一系列娇小的、连续的子序列,每个段具有固定的长度,使得模型在处理这些较短的段时,能够保持较低的内存需求和计算复杂度。这种分段方法避免了一次性加载和处理整个无限长序列的挑战,允许模型以流式(streaming)方式逐步处理输入,即每次仅处理一个或几个段,而非一次性加载全部数据。
在每个分段内部,无限注意力模型采用局部注意力机制来处理该段内的上下文信息。局部注意力限制了模型对当前段内token之间的注意力计算范围,通常采用因果(causal)或自回归(autoregressive)的形式,确保模型在处理当前token时,只能看到该令牌之前的所有token,而不能看到未来(即当前token之后)的任何token。
在输出结果时,无限注意力模型为了生成最终的上下文输出,要从压缩记忆中检索到的长期记忆信息与当前局部注意力计算出的上下文结合起来。这种融合确保模型既考虑了当前输入段的局部依赖,又充分利用了历史输入的长期上下文。
当你理解了无限注意力机制后再回到标题,无限注意力模型能够以流式方式处理极端长的输入序列,无需一次性加载整个无限长的输入,而是会根据历史记录进行分批次处理。那对于模型来说,就能够在有限的内存和计算资源约束下,适应并处理无限长度的上下文。
论文首先在长上下文语言建模基准上评估了无限注意力模型的表现,与包括transformer-XL在内的多种模型进行了对比。

采用无限注意力的模型在PG19(长文档数据集)以Arxiv-math(数学数据集)上都取得了远超于transformer-XL的结果,同时实现了114倍的内存压缩率,在保持低困惑度的同时提高了模型效率。
为了进一步验证无限注意力机制的性能,论文将一个10亿参数的大语言模型进行改造,把这个模型的多头注意力(MHA)模块换成了无限注意力,并继续对其进行预训练。验证过程是,团队要求模型在长达100万tokens的输入中定位并检索隐藏的密钥信息。
预训练阶段,模型使用的输入序列长度仅为4K个tokens,以适应无限注意力的处理模式。经过3万步的预训练后,对密钥检索任务进行微调。在微调阶段,为了模拟实际应用中可能遇到的更长上下文环境,模型在包含5K个token的长度输入上进行微调。
在完成预训练和微调后,团队对模型进行评估,在不同长度(从32K到1M)和不同密钥位置(开始、中间、结束)的长输入文本中检索密钥的准确性。实验结果表明无限注意力模型在所有测试场景中均能成功找回隐藏的密钥,展现出其对极长上下文信息的卓越处理能力。
随后团队为了证明无限注意力机制在更大参数模型上的表现,又对一个用无限注意力改造的80亿参数大语言模型进行了预训练。使用8k个token长度的输入训练了3万步。模型在BookSum数据集上进行微调,输入长度设置为32K用于微调,但在评估阶段增加到500K。
根据无限注意力在50万文本长度的图书中里生成的摘要,模型超越了专门为摘要任务构建的编码器-解码器模型及其长上下文扩展版本,实现了在BookSum数据集上的新SOTA(state-of-the-art)性能。随着输入书籍文本量的增加,模型的摘要性能指标(如Rouge分数)呈现出明显的上升趋势。
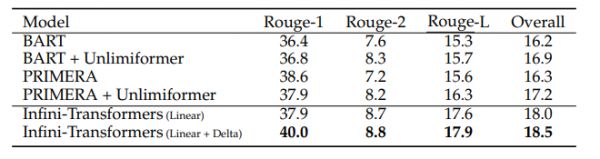
一个有效的记忆系统不仅对大型语言模型理解长文本来说是至关重要的,虽然论文并没有大刀阔斧地修改transformer模型的注意力机制,只是用了类似于微创手术一样的手法,把压缩记忆模块紧密地集成进了模型的标准点积注意力层(vanilla dot-product attention layer),却彻头彻尾改善了Transformer模型在处理长序列时碰到的问题。
2022年的时候,Deepmind曾发文《∞-former: Infinite Memory Transformer》,论文提出了一个叫做∞-former的模型,通过利用连续空间注意力机制对长期记忆进行关注,让模型的注意力复杂度变得与上下文长度无关。从方法上来看,无限注意力和∞-former是有些相似的。后者以牺牲精度为代价换取了记忆长度,可是无限注意力却可以在极端长度的密钥中找到关键信息,精准度甚至比以往要高很多。
其实归根结底,无限注意力和∞-former都是对Transformer的记忆系统进行改进。不过transformer有一大缺陷是不能处理非连续的数据。因为Transformer最初的设计是用于处理自然语言这样的连续文本序列,但随着图片生成、音乐生成、视频生成等多个领域应用的崛起,模型为了应对多模态的数据结构就必须能够处理非连续的数据。谷歌若想扩大自己在多模态领域的领先地位,可能会开始数据结构方面的研究工作。
本文来自微信公众号:硅星人Pro(ID:Si-Planet),作者:苗正
相关推荐
真假“长文本”,国产大模型混战
Kimi爆火后,大厂角逐长文本
“前卫”文本的时代症候
谷歌发布Translatotron 3 模型:可绕过文本转换步骤
斯坦福等新研究:随意输入文本,改变视频人物对白,逼真到让作者害怕
脑机接口利器:从脑波到文本,只需要一个机器翻译模型
AI把小说变漫画?Lore Machine推出AI新工具,224万字文本生成1792张图
苹果iOS 15上线:“实况文本”来了,打游戏还可过滤通知
iOS 15最受欢迎的「实况文本」,为什么得到那么多人的喜爱?
专注 NLP+RPA+OCR,「达观数据」发布新产品“智能文本 RPA ”
网址: 还在卷长文本?谷歌直接把文本干到无限长了 http://www.xishuta.com/newsview115287.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



