TPU优势为何?如何优化AI运算?
来源:半导体产业纵横


为了应对庞大的矩阵运算,TPU应运而生。

由 Google 精心开发、被誉为专为 AI 精心设计打造的 Tensor 芯片,尤其将重点聚焦于 TPU。当我们打开这款卓越的处理器 ——Google Tensor 一探究竟时,会惊喜地发现其中容纳着强大的 CPU、出色的 GPU,以及具备卓越 AI 运算能力的 TPU(Tensor Processing Unit)张量处理单元。
TPU 处理器芯片是什么?
无论是手机还是电脑,当代计算机的通用架构皆为以图灵机为理念设计而成的冯・诺依曼架构。这一将程序指令存储器与数据存储器合并在一起的概念架构,自 1945 年提出以来,便一直沿用至今。
除了输入输出设备之外,该架构中还涵盖了三大结构,即存储器(Memory)、控制单元(CU)以及算术逻辑单元(ALU)。在电脑主机当中,控制单元(CU)和算术逻辑单元(ALU)皆被封装于中央处理器(CPU,Central Processing Unit)之内;而存储器则以多种不同形式散布,依据存取速度可划分为:暂存器(Register)、快取(Cache)、主存储器(Main memory)以及大量储存装置(Mass storage)。
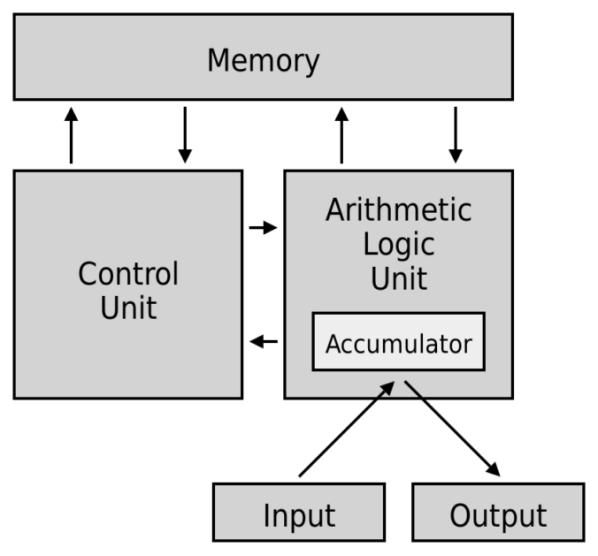
算术逻辑单元(ALU)主要负责运算工作,借助逻辑闸进行诸如加减乘除、逻辑判断、平移等基础运算操作,通过一次次的运算来完成复杂的程序。拥有了精密的算术逻辑单元之后,还有一项极为重要的任务,而这也正是控制单元(CU)最主要的工作 —— 流程管理。
为了加速计算过程,CU 会对任务进行分析,将需要运行的资料与程序放入距离 ALU 最近且存取速度最快的暂存器中。在等待 ALU 完成任务的同时,CU 会判断接下来的工作流程,预先将后续可能会用到的资料拉入快取与主存储器。并且在算术逻辑单元完成任务后,为其安排下一个任务,接着将半成品放置到下一个暂存器中等待下一步的运算。可以说,CPU 就如同一个工厂,ALU 则是负责加工的机器,而 CU 就像是流水线上的履带与机械手臂,持续地将原料与半成品运送至下一站,同时掌控着工厂与仓库之间的物流运输,以实现效率的最大化。
然而,随着科技的不断发展,人们需要电脑处理的任务量日益增大。以照片为例,随手拍摄的一张 1080p 相片就包含 1920×1080 共计 2073600 个像素。不仅如此,在彩色相片中,每一个像素还涵盖 R、G、B 三种数值,如果是具有透明度的 PNG 图片,还会多一个 Alpha 值(A 值),这意味着一张相片就有 800 万个元素需要进行处理,更不用说如今很多手机都已经能够拍摄到 4K 以上的画质了,这对于 CPU 而言实在是过于繁重的任务。
由于 CPU 仅有一条生产线,所能做的就是增加生产线的数量。工程师们也发现,实际上在影像处理的过程中,瓶颈并非在于运算的题目过于困难,而是工作量极为庞大。CPU 固然强大,但处理量能不足该如何是好?
那就换狂开产线的GPU
与其着力增加算术逻辑单元的运算速度,倒不如对原有的工厂进行重新改建!在厂房中尽可能多地置入更多构造相同的流水线,而像仓库这种大型仓储空间则可以供所有流水线共同使用。如此一来,不仅能够提升单位体积中的运算效能,而且在相同的时间内,还可以产出更多的成果,减少处理一张相片所需的时间。
显卡大厂 NVIDIA 于 1999 年首次提出了将图形处理器独立出来的构想,并发布了历史上第一张专为加速图形运算而诞生的显卡 ——GPU(Graphics Processing Unit)NVIDIA GeForce 256。
在一颗 GPU 当中会有数百到数千个 ALU,就仿佛是将许多小型 CPU 整合在同一张显卡之上。在影像处理的过程中,CU 会将每一格像素分配给不同的 ALU,当处理相同的工作任务时,GPU 便能够大幅提升处理效率。
这也正是为什么在加密货币市场中的 “矿工” 们,大部分都选择 GPU 作为挖矿工具。由于矿工们实际所进行的计算并不艰难,关键在于需要不断反复计算,以处理具有庞大工作量的 “工作量证明机制” 问题,而利用 GPU 进行加速无疑是最佳解决方案。
不过,随着时代的发展,影像处理技术的需求变得更加复杂,这便进入了人工智慧的范畴。就以一张相片为例,要能够识别出相片中的人物是谁,就需要有一道处理工序来进行比较、综合资讯以实现人脸辨识。如果要提升准确度,就必须不断加入参数,比如眼镜的有无、脸上的皱纹、发型等,除此之外,还需要考虑到人物在相片中的旋转、光线造成的明暗对比等因素。
每一次的参数判断,在机器学习中都是一层不同的过滤器(filter)。在每一次计算中,AI 会拿着这个过滤器,在相片上从左至右、从上至下,去探寻相片中是否有符合这个特征的内容。每一次的比对都会给出一个分数,总分越高,就代表这附近有越高的机率符合过滤器想要寻找的对象,就如同玩踩地雷游戏一样,当这里出现高分数的时候,就意味着找到了目标。
而这种方式被称为卷积神经网络(Convolutional Neural Networks, CNN),它是神经网络的一种,被大量应用于影像辨识当中。除了能够增进影像辨识的准确度之外,通过改变过滤器的次数、移动时的快慢、共用的参数等,还可以减少矩阵的运算次数,加快神经网络的计算速度。
然而,即便如此,其工作量仍然比传统影像处理复杂得多。为了应对庞大的矩阵运算,我们的主角 TPU(Tensor Processing Unit)张量处理单元便应运而生了!
TPU 如何优化AI 运算
既然卷积神经网络(CNN)的关键在于矩阵运算,那么不妨打造一个在矩阵运算方面速度极快的芯片吧!
TPU 在处理矩阵运算时采用了脉动阵列(Systolic Array)的方式。与 GPU 中每个 ALU 各自为政不同,在 TPU 中,数据会在各个 ALU 之间穿梭流动,每个 ALU 专门负责一部分任务,共同协作完成整体任务。这样做有两大好处:其一,每个个体承担的工作量更少,意味着每个 ALU 的体积可以进一步缩小;其二,半成品传递的过程能够直接在 ALU 之间进行,无需再将半成品暂存在特定区域后又取出,从而大幅减少了存储与读取的时间。
在这样的架构下,与只能容纳约 4000 个核心的 GPU 相比,TPU 能够塞进 128×128 共计 1.6 万个核心。再加上每个核心承担的工作量更小,其运算速度更快,耗电量也更低。我们日常频繁使用的谷歌服务,有许多都通过 TPU 进行了优化,例如本身就是全球最大搜寻引擎的谷歌、谷歌翻译、谷歌地图等,都大量运用了 TPU 和神经网络来加速。
2021 年,谷歌更是将 TPU 引入到自家手机产品中,也就是前面我们所提到的 Google Tensor。今年,在 Pixel 7 中更是放入了升级后的 Google Tensor G2。
谷歌表示,新款人工智能芯片能够加快 60% 的机器学习速度,还能加快语音助理的处理速度并增加其功能,在通话时去除杂音以提升通话品质等。不过,最令人有直观感受的还是图像处理方面,比如通过 AI 新增了修复模糊处理功能,不仅可以修正手震造成的模糊,还能让旧相片也变得清晰起来。
如今新款手机为了凸显自身的不同之处,越来越强调自家芯片设计与效能的差异。除了谷歌的 TPU 之外,其他公司也朝着 AI 芯片的方向迈进,包括苹果、高通、联发科、中国的寒武纪等,也都发布了自行研发的神经网络处理器(NPU)。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。
相关推荐
TPU优势为何?如何优化AI运算?
TPU芯片:国内面对AI大模型的另一种解法
强攻GPU,TPU芯片一夜蹿红
为什么谷歌不学英伟达,卖自己的TPU?
中国AI芯片突破!全球首款碳基TPU问世,碳基AI时代或将来临?
TPU正面挑战GPU:果然“天命人”?
从谷歌TPU,看AI芯片的未来
谷歌千元级TPU芯片发布,TensorFlow更换Logo推出2.0最新版
“AI芯片”通识:AI产品经理看这一篇就够了
谷歌TPU秘密武器,6小时完成芯片布局,新AI算法登Nature
网址: TPU优势为何?如何优化AI运算? http://www.xishuta.com/newsview126273.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



