全球最强开源AI大模型诞生:中国研发,成本只有Deepseek的30%
众所周知, 自从OpenAI的ChatGPT发布之后,全球就进入了千模大战。
而自从Deeseek推出之后,这些大模型们,又掀起了开源高潮,因为大家发现,开源的大模型,更能够得到大家的使用。
但与此同时,在AI大模型方面,也有两个方向,一个就是OpenAI们,那就是大力出奇迹,狂堆GPU卡,用算力来堆出高性能AI。

毕竟像OpenAI、马斯克的AI们,它们又有钱,又能买到最强的GPU卡,没必要没苦硬吃,堆显卡就是了。
而另外一个方向,则是像Deepseek一样,钱不多,且显卡也受限,只有“四两拨千斤”,用最少的显卡,办最大的事,做出最强的性能。
所以Deepseek打的华尔街是溃不成军,因为用的显卡少,性能却最强。

但近日,又产一国产大模型,甩出了王炸,因为它的成本更低,但性能却超过了OpenAI-o1模型,也超过了Deepseek-R1等,登顶全球第一。
这个模型,就是阿里通义千问大模型 Qwen3(简称千问 3),并且这个也是开源模型。
千问3,也是全球首个“混合推理模型”,将“快思考”与“慢思考”这两种模式集成于同一个模型之中,根据不同的需求,进行灵活处理,比如简单问题,就快思考,复杂问题就“深度思考”或者说“慢思考”。
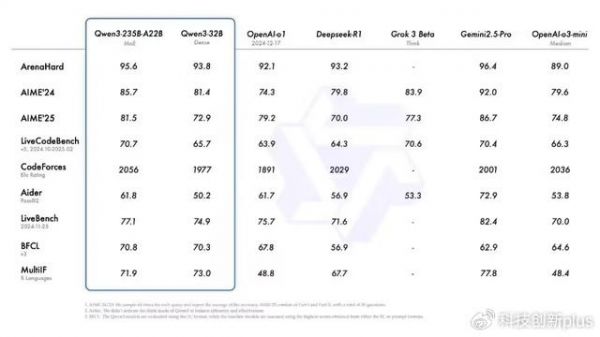
不仅如此,最让大家兴奋的是,千问 3 在性能和成本控制上实现了惊人的跨越 ,他只需要 DeepSeek-R1 三分之一的参数规模,也就是说成本低了三分之二,性能却实现了超越。
具体的来讲,只需要4张H20这样的显卡,就能够部署全功能的千问3模型了,显存占用量,也仅为同类模型的三分之一,部署成本仅为满血版 DeepSeek-R1 的 25% 至 35%,降低了门槛。

自从Deepseek推出,国内就进行了一大波的国产GPU替代,因为大家发现不需要英伟达最强大的显卡,也可以部署强大的模型,一度打破了OpenAI的神话,也打破了英伟达的算力泡沫。
如果千问3来袭,估计国产GPU替代会再次加速了,因为既然不需要顶级的AI算力,国产GPU当然就能够顶上了,所以国产GPU肯定是又迎来了大机会。
发布于:湖南
相关推荐
全球最强开源AI大模型诞生:中国研发,成本只有Deepseek的30%
大模型界的“拼多多”——DeepSeek,为何能重塑AI行业?
DeepSeek大模型专家交流
DeepSeek促AI开源浪潮涌动
AI共富:DeepSeek震惊美国AI业界,中国国产AI大崛起!
谷歌前CEO评DeepSeek:它标志着全球AI竞赛的“转折点”
中国最强AI研究院的大模型,为何迟到了
DeepSeek开源周:开源可能是不想赚钱,也可能是想推动更大变化
中国最强AI研究院的大模型为何迟到了
DeepSeek,中国AI的“斯普特尼克时刻”?
网址: 全球最强开源AI大模型诞生:中国研发,成本只有Deepseek的30% http://www.xishuta.com/newsview135513.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



