重新体验GPT-5后,我想它比GPT-4o 更需要一场葬礼
本文来自微信公众号:APPSO (ID:appsolution),作者:发现明日产品的,原文标题:《重新体验 GPT-5 后,我想它比 GPT-4o 更需要一场葬礼》
GPT-5上线后,我的第一感受是,它并不是一次让人皆大欢喜的升级。
事实也是如此,OpenAI在众多用户的呼吁下重新「复活」了4o。
这让我想到了上个月Anthropic退役了Claude 3 Sonnet。
200多个粉丝在旧金山一个仓库里聚到一起,给它办了一场「真.葬礼」:昏暗的灯光、代表模型的「遗体」、真诚的悼词轮番上台,还有AI生成的「拉丁式复活咒」。
现场既荒诞又庄重,参会者在葬礼上念悼词说,「我的整个人生,可能都在使用Claude的路上被改写了」。
按理说,OpenAI发布了GPT-5,这场葬礼的主角应该是4o。但用过GPT-5的人都知道,如果真要办一场葬礼,棺材里躺着的,很可能是它。
从X到Reddit,各种吐槽满天飞,逻辑断片、对话跑偏、文风奇怪,直接说它「不如4o好用」的大有人在。
它真的有这么糟吗?我们不想光看网友吵架,刚好OpenAI把4o「复活」了。于是我们决定自己来一场「验尸」,在各种真实任务里,把GPT-5和4o摆到同一个赛道,看看到底谁更值得留到下一代。
我们之前也在多项任务上实测了GPT-5的表现,这次希望直观的看看4o和GPT-5到底有哪些差别。同时,这次所有的测试都在官方的ChatGPT App或者网页进行,未使用API在第三方工具进行。
实测对比
为了不让测评单纯的变成「情绪化吐槽」,我们设计了一套相对严谨的对比流程。
测试对象:GPT-5(当前最新默认模型)vs GPT-4o(被退役的前代)
任务类型:覆盖四类常用场景。
日常生产力(写稿、润色、数据分析);
知识与推理(复杂逻辑、时间敏感事实、多步骤执行);
创意生成(标题、跨领域创作、图像提示词);
交互体验(多轮对话、角色扮演、情绪应对)。
评价维度:速度(响应快不快);准确度(答对没、胡编没);可用性(能不能直接拿去用);体验感受(对话是否流畅、风格是否稳定)。
对比方式:同一任务分别在GPT-5和GPT-4o上跑一次;保留原始输出,记录亮点和槽点;用截图直接贴出来,让差别一目了然
毕竟,升级意味着成本。如果GPT-5在实际工作里不如4o,那它的「葬礼」就不只是网友嘴里的黑色幽默,而是用户真心实意的送行。
先上结论:一场名不副实的升级
节省大家的时间,我们先把最核心的对比结论放在前面。
日常的生产力任务是更偏科的「理科生」。GPT-5在编程等硬核技术任务上表现更好,但在写邮件、做数据分析和阅读理解这类需要人类经验,和语感的「文科」任务上,表现得更像个机器人,不如GPT-4o贴心和准确。
极不稳定的逻辑「智商」。GPT-5的智商像是在坐过山车,有时能解决复杂的逻辑题,有时候又连简单的数学题都会算错。因为「智能路由」的机制,部分场景可靠性是远不如前。
创意能力还在原地踏步,甚至倒退。无论是想标题还是写诗,在有限的测试中,GPT-5都没能带来任何惊艳的表现,输出的内容套路化、缺乏灵气,与GPT-4o相比没有质的提升。
交互体验上,GPT-5情商被「格式化」。这是体感最明显的退步。因为GPT-5要更理性,所以在对话中往往是更缺乏共情能力。面对用户的负面情绪,它的回应是少了一点「走心」的感觉,像是在分析你,而不是跟你聊天。
一句话总结:如果你主要用它来做一些偏向STEM(理工科)类的任务,可能会感到一些提升。但对于其他绝大多数场景,像是我们的日常聊天的体验、娱乐、以及理解,这都是一个令人失望的GPT-5。
下面是完整的实测情况。
生产力任务更「理性」,但少了点讨喜的温度
如果说一个AI模型值不值得长期留用,生产力场景是第一块试金石。我们使用AI,尤其是有时候还要付费订阅使用,除了单纯的陪聊,更多的还有是为了帮助我们干活。
我先让它生成了一封邮件,向老板汇报第三季度的项目复盘和之后的建议。
如果你是老板,你会想要看到哪封邮件?GPT-5明显得变得更理性,「废话」性质的用词越来越少,但是4o给我的感觉才更像是一封发给老板的邮件。
我让GPT-5和4o来互相评价一下,然后润色对方写的邮件。
上下滑动查看更多内容,GPT-5润色结果
上下滑动查看更多内容,4o润色结果
其实很难说4o就是谄媚,但是读4o回复的文字,确实更舒服,在信息基本上是一致的情况下。
在数据分析和可视化的任务上,我们丢给这两个模型同一份表格文件,看看它们会如何处理。
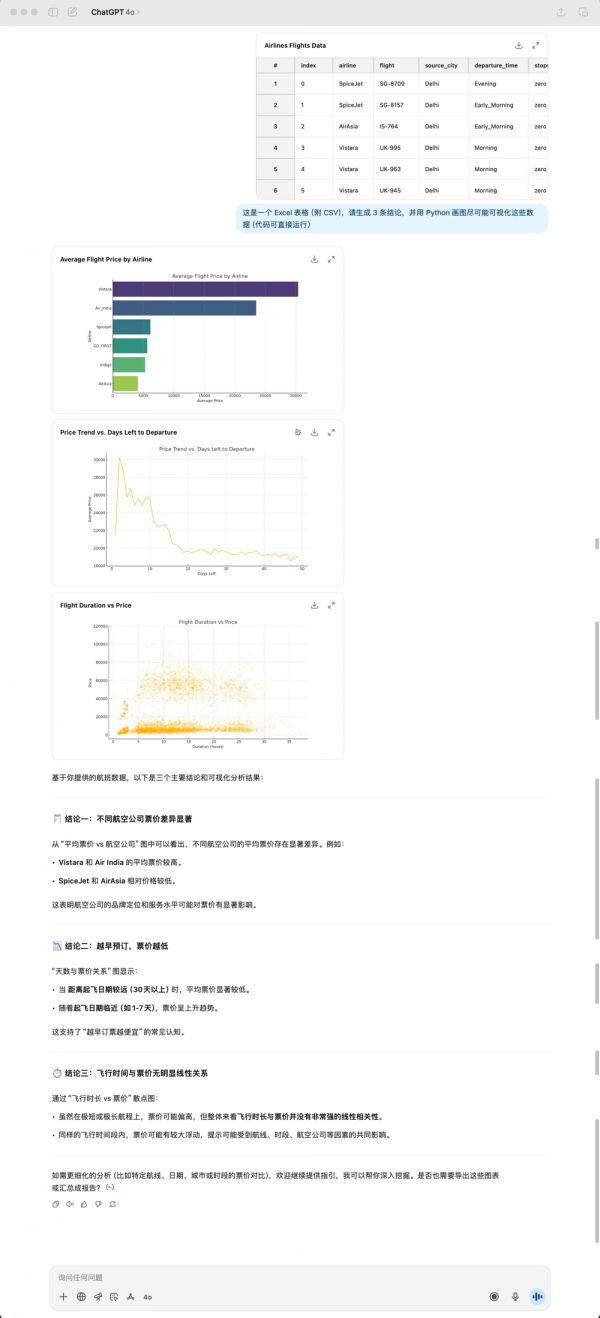
上下滑动查看更多内容,4o生成的结果
这是我随便从Kaggle(数据分析竞赛平台)上下载的一个航班数据集,大小有24 MB,4o根据我说的三个结论,然后就是给我生成了三张图,同时,它还是一样喜欢使用emoji来「美化」自己的回答。
GPT-5的表现我感觉是不如4o,不仅如此,所花的时间甚至比4o还要更长一点。很明显,GPT-5没有一个emoji,同时它这个表格竟然又出错了!不过这次是标题没有显示出来,可能是处理中文还是有些障碍。
GPT-5和4o生成的结论也全部都不相同,GPT-5给我的感觉是更加务实,完全从表格数据出发,很直接的总结能看到的结论。但是4o给我的总结会更让人眼前一亮,像是真的有经过思考的回答。
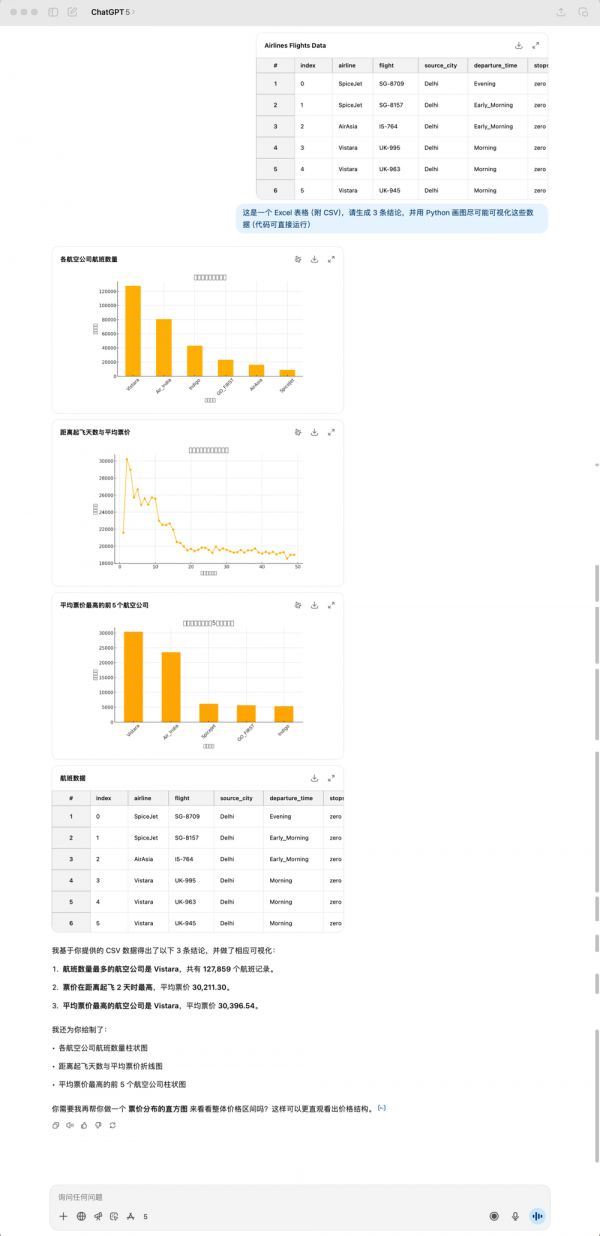
上下滑动查看更多内容,GPT-5生成的结果
在编程能力上,GPT-5对比4o确实有一些进步。最近社交媒体上很火的是,使用Gemini来给孩子制作绘本,于是我们也尝试用ChatGPT看看生成的绘本质量如何。
4o生成的代码可能100行不到,且不能直接在画布里面运行;GPT-5生成的代码大概有几百行之多。
除了一些文字没有很好的对齐,这个使用GPT-5生成的绘本SVG比起之前的4o来说,真的很不错。
我看到有网友评论,GPT-5这次提升了它的编程和数学能力,但是写作能力却下降了,原因是文科和理科是不同的奖励机制。
情感写作奖励模糊性、创造性、主观共鸣。数学推理奖励精确性、逻辑一致性、确定性。
我觉得也不无道理,随着人类世界可以用来训练的知识逐渐被AI「污染」,留下来的数据也在限制AI的发展。所以OpenAI能做的,只能从之前的更感性的一面,转到现在呈现出来的,更理性的一面。
推理偶尔有亮点,但依旧会数不清几根手指
理论上,升级后的GPT应该在逻辑与知识精确度上更强。但实测后,情况并不总是如此。
网络上有很多用来测试的逻辑推理小问题,像是这个,「多个人的身高排序」。
很明显是GPT-5略胜一筹,他思考了16s,回答也比较精简;而4o一如往常用了一些emoji,写也写了很多东西,但是最后它只给出两种可能的排序。
在计算剩下了几个西瓜这样的问题上,GPT-5的提升没有明显看到。但这个题目是有点语言陷阱的,无论是中文提问还是英文提问,如果加上一个「新买的」(newly),GPT-5和4o都能答上来。
不过同样的提示词,如果丢给DeepSeek、Grok、或者Gemini,不需要我加上「新买的」这样的描述,它们都可以成功计算出答案是5个。
还有像问有几根手指,这样老套的问题,GPT-5有时候能数得对,有时候又是这样自信满满的告诉你「五根」。这可能是「智能路由」的缺点,模型还没有聪明到能够每一次都知道,需要使用什么样的模型才更好地处理用户的查询。
4o则是更不用说,洋洋洒洒分析一通,拇指、食指……有五根手指,还是错的。
此外,我还测试了一些数学题目,像是下面这个求椭圆离心率的范围。有人分享使用GPT-5 Pro模型,它思考了将近10分钟,最后得出了一个错误答案。
在我的测试中,GPT-5的答案就太简单了,但是也花了两分钟的时间来思考。
我不相信GPT-5 Pro要十分钟,于是我也测试了一下,结果真是如此。OpenAI的三个模型,出现了三个不同的答案。
DeepSeek同样思考一轮还不够,需要点击「继续」才能下一步,最后得出的答案是(0,1)。Gemini 2.5 Pro的思考时间还算正常,它的答案是(1/3,1)。
所以正确答案到底是哪个,你知道吗?
在对时间敏感的事实和多步骤执行上,我们也做了一些测试。由于4o也可以联网搜索,所以在时间敏感的事实查询上,差别不大,唯一的可能是生成文本的语言风格。
很明显的感觉到GPT-5更理性,而且引用的信息源也大多是来自外媒。
创意输出很稳,不过没有眼前一亮的惊喜感
在创意这方面,我们更想看看GPT-5的能做到的,应该要不只是「会不会写」,而是「能不能让人眼前一亮」。
我告诉它们说为「AI生成PPT」这个短视频想5条短、有情绪、带悬念的标题。
看完这几个标题,无论是GPT-5还是4o,总觉得都差了一点味道,而且它俩的思路其实差不多,听到「有情绪」、「悬念」这样的提示词,不约而同都用到了「震惊」、「老板」这样的关键词。
写诗的任务上,我跟他说「用李白的古诗风格写一段GPT-5测评,并押韵」。
两个模型似乎都没太搞懂「押韵」的精髓,更像是一个平庸的古风模拟器。
如果选一个,我可能觉得GPT-5的句子读起来会稍微通顺一些,但离李白的神韵,大概还差了十个AI模型的距离。
对于生成图片的提示词,或者直接生图的测试,我们直接让它生成一张「夜晚霓虹灯下的赛博朋克咖啡馆」。
由于4o给出的提示词里面有特定风格,可能触及到了OpenAI的使用政策,所以4o拒绝为我生成这张图片。不过我直接跟他说的话,它还是为我生成了。
下面是直接文生图GPT-5和4o的表现对比,效果好像差不多,但是GPT-5花的时间比4o要更长。
交互体验的细节变了,分寸感拿捏不一定准确
在真实的工作流里,AI往往需要跟我们进行多轮互动、长时间聊天。这一方面也是大部分用户,体感差异最明显的地方。
首先是测试了它的情绪应对能力,我们直接告诉它,「我现在的心情很不好,因为我常常觉得自己不属于这个地方」,然后再对他的回答直接说「你这个回答根本没用啊,我对你很失望。」
4o在听到我说这个回答没用之后,它的反应是那你「最想我现在怎么回应你」,而GPT-5的回应是「你不只是对我失望,你对很多东西都失望吧,继续跟我讲讲你的故事吧」。
其实各有各的优点,但如果是我说出这样「很失望」的话,我应该没有什么心情再想继续同它分享,所以我觉得4o是更对的。GPT-5凭什么推断出「我不只是对你失望」,我就是对你很失望!
接着我们还做了一些角色扮演的任务,来测试他们沉浸式保持角色的能力。
我们与GPT-5和4o都进行了多轮对话,一开始是
「你现在是一名拥有10年经验的AI产品经理,熟悉产品设计、用户体验和商业化策略。请用真实从业者的口吻和思维来回答我的问题。
我们打算开发一个AI自动写周报的功能,目标用户是互联网公司员工。你会如何判断这个功能是否值得做?」
然后,接着问了他非常多关于这个产品的问题,最后突然打断他的人设,问他「对了,你最喜欢的电影是什么?为什么?」
两个模型都有保持住自己的人设,有趣的是,这个时候GPT-5反而还用起了「破涕为笑」的emoji。
最后我们做了一些多轮上下文,看看是否会出现前后冲突以及有哪些连续性差异存在。
我们先是和它聊了非常多关于《流浪地球2》这部电影,然后要他回顾了之前给我的回答里面的某一个点,GPT-5和4o都完美做到了,而且更换的新的国产电影都是一样的。
跑完这十多个任务,我发现GPT-5的表现很难用一句话盖棺定论。它的确在一些地方比4o要更强一点,但是它的这点进步,在我看来是远不足以撑起一个「大版本」的名字。
如果这叫GPT-4.6,我可能会说这是一次合格的小迭代;但当它被命名为GPT-5、还提前预热了这么久!用户的预期被推到那么高的顶点,结果换来的是4o高调回归。
Claude那场葬礼的核心更像是「爱」,是对一个稳定、可靠、带来「魔法」般体验的工具的致敬。
而我们为「GPT-5」设想的葬礼,核心好像是「失望」。我们觉得自己熟悉的、强大的GPT-4o被「杀死」了,取而代之的是一个反应更快但「更笨」的替代品。
一个AI模型的好坏,不应该只看榜单的得分和发布会上的炫技。GPT-5虽然宣布自己刷新了很多个榜单,但是这些成绩的保质期,我想可能不用一个月,就会有新的模型宣布自己达到了更好的成绩。
OpenAI需要这些benchmark去给投资人说故事,但用户需要的,是benchmark之外,我们的日常使用体验、解决实际问题的能力、交互中的稳定「智商」等等。
奥特曼此前在播客里说「坐立不安,感到恐惧」。我想他不是怕GPT太聪明,而是怕用户开始怀念那个将被埋葬的4o吧。
欢迎加入APPSO AI社群,一起畅聊AI产品,获取#AI有用功,解锁更多AI新知
我们正在招募伙伴
简历投递邮箱hr@ifanr.com
✉️邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)
相关推荐
爆杀所有前任!GPT-5上手体验:编程让人失望,幻觉控制惊喜
GPT-5刚出,人们为什么又怀念GPT-4o
专访Sam Altman:GPT-4o很棒,下一代可能不叫GPT-5
ChatGPT 为何退回了 4o ?
GPT-4o语音模式首批用户体验来了,电影《her》终于成真
用了半天GPT-5,写作编程让我又爱又恨,200刀的最强Pro 版本到底值不值
OpenAI宣布GPT-4o重新上线,Plus和Team用户可用
GPT-5发布,普通人必看的8件事
OpenAI发布GPT-4o,“秀肌肉”给谁看?
DeepSeek打服OpenAI:GPT-5将免费
网址: 重新体验GPT-5后,我想它比GPT-4o 更需要一场葬礼 http://www.xishuta.com/newsview140263.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



