GLM-4.5技术报告揭秘:如何围绕Agent构建一个模型
本文来自微信公众号:硅星GenAI (ID:gh_e06235300f0d),作者:周一笑
智谱GLM-4.5的发布,在近期的AI开源社区中引发了不小的讨论。模型放出后,它在Hugging Face社区的趋势榜单上表现亮眼,综合性能也在多个基准测试中位列前茅。其原生Agent能力的提法和颇具竞争力的定价,都成为了开发者们关注和讨论的焦点。
在模型获得了一波社区的实践和反馈之后,智谱紧接着发布了长达25页的详尽技术报告。这份报告同样获得了很高的关注度,登上了Hugging Face Daily Papers的热度榜首。
这份报告的价值在于,它系统性地阐述了其模型的设计思路,明确将Agent、Reasoning(推理)和Coding(代码)三种能力的统一,即ARC,作为衡量通才模型的核心标准。
报告链接:https://github.com/zai-org/GLM-4.5/blob/main/resources/GLM_4_5_technical_report.pdf
ARC三位一体
GLM-4.5的设计哲学的核心聚焦于Agent、推理和代码三者的原生统一。报告在开篇就明确提出了这个主张。它认为,大语言模型(LLM)正从通用知识库演变为通用问题解决者,一个真正的通才模型,需要统一掌握三项相互关联的核心能力:
Agentic abilities(Agent能力):与外部工具和真实世界进行交互。
complex Reasoning(复杂推理能力):解决数学、科学等多步骤问题。
advanced Coding(高级代码技能):处理真实的软件工程任务。
这三者之间存在着紧密的内在逻辑。一个强大的Agent,必须具备调用工具的能力,而代码(Coding)正是与数字世界交互的终极工具;同时,要完成一个复杂任务,例如根据用户需求去修复一个GitHub仓库里的Bug,必然需要严密的逻辑推理(Reasoning)能力来规划步骤和理解依赖关系。
因此,GLM-4.5的设计目标就是将这三者进行原生集成,让Agent能够基于优秀的推理和代码能力,去思考和行动,后续大量的技术细节,都是围绕这个目标展开。
为Agent打造的技术路径
一个清晰的目标,需要一条严谨的技术路径来实现。GLM-4.5的技术报告用大量篇幅介绍了其如何从模型架构、数据处理、训练流程到最终的强化学习,一步步地将Agent能力注入到模型中。
模型架构:更深、更专的MoE设计
GLM-4.5采用了当前大模型领域主流的混合专家(MoE)架构,以在保证性能的同时提升计算效率。报告揭示了其在具体实现上的一些独特设计选择,例如“瘦高”结构。与一些模型追求更“宽”(更多的专家数量、更大的隐藏层维度)不同,GLM-4.5团队选择了减少宽度,但增加模型深度的结构。报告提到,他们发现更深的模型在推理能力上表现更出色,这直接服务于ARC能力中的推理基础。此外,报告还提到了一些为增强推理能力而做的精细调整,例如模型使用了倍数于常规模型的注意力头,并引入QK-Norm技术来稳定训练。这些改动共同为模型打下了坚实的推理和代码功底。
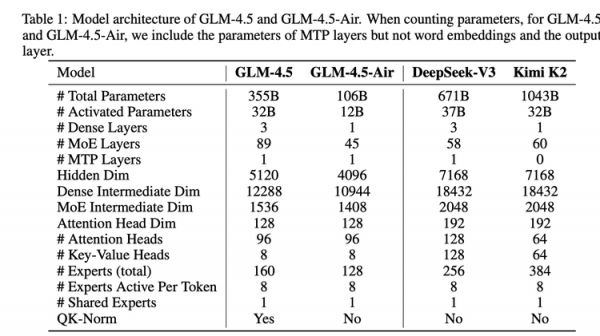
GLM-4.5与DeepSeek-V3与Kimi K2的模型架构对比
训练流程:从“广积粮”到“中场强攻”
一个好的模型架构需要海量且优质的数据来喂养。报告详细介绍了其复杂的多阶段训练流程,清晰地展示了从通用到专精的演进过程。在两阶段预训练中,模型先在15T Tokens的通用语料上进行学习,可以理解为“广积粮”。随后,则在一个7T Tokens的数据集上继续训练,这个数据集会重点上采样与代码和推理相关的高质量内容,相当于开始为ARC能力“定向施肥”。
报告中一个非常有趣的环节是独特的中期训练(Mid-training)。在完成大规模预训练后,模型会进入一个专门的“中期训练”阶段,针对性地“强攻”特定能力。这个阶段主要包含三类数据:一是代码仓库级数据,将同一个代码库的多个文件拼接训练,让模型学习跨文件的依赖关系;二是合成推理数据,利用已有模型生成大量带有推理过程的问答数据;三是长上下文与Agent轨迹数据。这是最关键的一步,模型开始接触并学习大量的、由机器合成的Agent任务轨迹,同时训练的序列长度也从预训练时的4K,一路扩展至最终的128K。
Pre-training和Mid-training的多阶段流
后训练:RL注入Agent灵魂
如果说预训练和中期训练是为模型打造了强健的“躯体”,那么后训练,特别是强化学习,则是为其注入“灵魂”的关键。正如一位社区开发者评论的那样,这份报告的大部分篇幅都在讲述一个复杂的后训练策略。
报告中的RL训练设计,处处体现出为Agent服务的思想。例如,Agentic RL的训练聚焦于两类可以被程序自动验证结果的任务:基于信息检索的问答和软件工程,因为这类任务有明确的成功或失败信号,便于模型进行高效的强化学习。报告中一个值得注意的细节,是为模型的工具调用设计了一套新的XML格式模板,旨在解决常见JSON格式在参数包含代码时需要大量转义字符的痛点,直接提升了Agent最核心的工具调用环节的稳定性和效率。
另一个例子体现在模型的交互式解决问题能力上。如下图所示,在网页浏览这类典型的Agent任务中,模型的准确率会随着与环境交互轮次的增多而稳步提升。这说明模型学会的不是一次性地给出答案,而是通过持续的探索、试错和信息整合来逼近正确解,这正是Agent模式的核心价值所在。
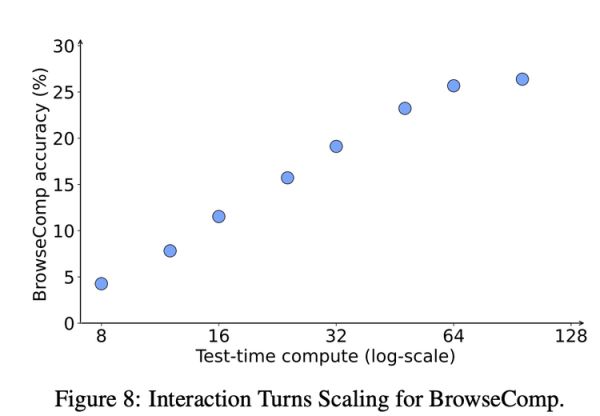
BrowseComp模型的准确率随交互轮次(测试时计算量)的增加而变化。
为了支撑如此复杂的RL训练,智谱还专门设计并开源了名为slime的RL训练框架。根据报告描述,这个框架的核心设计(如异步、解耦的训练架构)就是为了高效处理Agent任务中常见的数据生成慢、交互耗时长的痛点,体现了其构建开发者生态的意图。
总体来看,GLM-4.5的技术报告用详尽的数据,对其以Agent为核心的设计理念进行了验证。
报告的评测部分体现了模型综合性能。在涵盖Agent、推理、代码的12项基准测试中,GLM-4.5的综合得分位列全球第三,Agent能力单项排名全球第二。
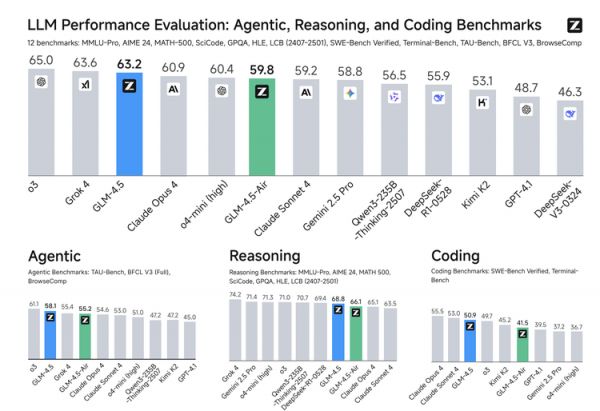
报告还提供了更深入的Agent能力评测细节。例如,在一个名为CC-Bench的真实编程任务测试中,GLM-4.5的工具调用成功率达到了90.6%,超过了多个强有力的竞争对手。这种在实际任务中表现出的高可靠性,也让一些海外开发者评价其为“当今最精通工具、最原生的Agent模型”。
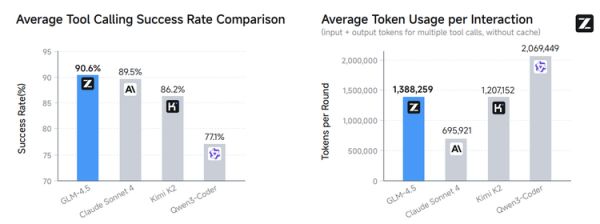
不同模型在CC-Bench上的平均工具调用成功率与单轮交互的平均Token消耗对比。
社区的讨论也指向了另一个维度:性价比。有用户评论认为,“性价比才是大模型落地的真正核心指标”。这一点与GLM-4.5的技术选型不谋而合。其采用的MoE架构本身就是一种平衡效果与成本的高效方案,这种技术效率也反映在了它的市场策略上,使其能以一个普惠的价格,鼓励更多开发者进行调用和尝试,形成生态的正向循环。
这份技术报告,本质上是智谱将其以Agent为核心的设计思路,完整地摊在了桌面上。当模型权重、技术报告、以及RL训练框架slime三者同时被推向社区,其意义就不再只是发布一个供人调用的工具。这更像是一种开放的邀请,开发者不仅可以“用”这个模型,更可以深入地“学”它的实现方法,甚至“改”它的训练流程。这或许是更深层的价值所在。
相关推荐
GLM-4.5技术报告揭秘:如何围绕Agent构建一个模型
夸克生成千万份志愿报告背后:一个Agent应用“深度落地”的真实样本
AI Agent,大模型变现的首把钥匙?
90%被大模型吃掉,AI Agent的困局
微信支付宝,开打Agent
法本信息AI Agent技术赋能垂直行业智能化
从大模型到Agent,游戏规则会改变吗?
万字长文,聊聊下一代AI Agent的新范式
零一万物押注企业级Agent,李开复也做起“推销员”
中关村得助大模型平台2.0发布:算力统一调度、5分钟构建应用
网址: GLM-4.5技术报告揭秘:如何围绕Agent构建一个模型 http://www.xishuta.com/newsview140297.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



