不要再看英伟达的热闹了!中国的量子计算正被美国快速甩开
10月28日,在NVIDIA华盛顿GTC大会上,黄仁勋带着他的一系列“新品”,又一次拉高了股价。其中,他正式发布了名为NVQLink的新型互联架构,并宣布了与美国能源部(DOE)在构建AI超算方面的重大合作,勾勒出一幅由“加速计算+AI+量子计算”三大平台共同驱动的未来科研图景。
我们先来客观分析下英伟达的量子新产品,从别人家的热闹背后,看看目前我们跟美国是否真的走到了一个分岔口,下一个路口,我们是否还能碰到?
当前的量子计算还是处于NISQ时代,无论这些先进的量子处理器展示了多强的超越经典计算机的潜力,但还是逃不过“物理比特数有限”这个“硬伤”,因此极易受到环境干扰产生错误。这种内在的不稳定性正是量子计算走向实用化的最大障碍。
为了克服这一限制,实现容错通用量子计算(FTQC),唯一的途径是采用量子纠错(QEC)机制。QEC通过将多个易出错的物理比特编码为一个具有高度稳定性的逻辑比特,确保信息的完整性。然而,量子纠错本身对经典计算资源提出了极度苛刻的要求。
QEC循环需要对物理比特进行实时监控、测量错误综合征数据,并在极短的时间窗口内(通常在微秒甚至纳秒级别)通过复杂的算法进行实时解码和反馈控制。如果解码和反馈过程存在延迟,超过了量子比特的退相干时间,逻辑比特便会失效。
NVQLink的战略定位
在主旨演讲部分,黄仁勋宣布推出NVIDIA NVQLink。作为一种开放系统架构,NVIDIA NVQLink用于将GPU计算的极致性能与量子处理器紧密耦合,以构建加速的量子超级计算机。其核心目标是提供大规模量子计算和QEC所需的低延迟、高吞吐量连接。
 来源:NVQLink
来源:NVQLink值得注意的是,NVQLink的开放性是其核心战略价值。传统上,NVIDIA的NVLink是一种专有技术,主要用于GPU内部连接。但NVQLink采取开放架构,成功汇集了包括17家QPU制造商、5家控制系统制造商和9家美国国家实验室的广泛支持。通过制定这一行业互联标准,NVIDIA的目标不是直接竞争量子硬件,而是确保无论何种QPU技术最终获胜,都必须依赖NVIDIA的GPU和CUDA-Q生态系统进行加速计算和实时控制。这种基础设施赋能者的定位,帮助NVIDIA在未来的量子-AI融合市场中占据了不可或缺的中心地位。
此外,该架构的关键价值在于保证QEC循环的“确定性”。QEC需要可靠且可预测的反馈时间,以保证每次测量到反馈的时间波动极小。核心合作伙伴Quantum Machines强调,NVQLink支持“确定性、低延迟通信”。这意味着系统不仅要追求高速度,更要保证在极短时间内的稳定性和可靠性,这远远超出了传统网络“尽力而为”的模式,是构建工业级容错量子系统的基础。
为何需要新的链路?
了解到这里,我们心中不禁好奇,那在NVQLink推出之前,传统的量子处理器与AI超算是通过什么进行互联?它的效果能够到达什么样的水平?
在NVQLink出现之前,现有的高性能计算(HPC)互联技术无法满足QEC苛刻的实时性要求。
本文主要以传统NVLink和InfiniBand两种互联方式为例。
NVIDIA的传统NVLink(如第五代)专为单个服务器内部的GPU-GPU/GPU-CPU通信设计,提供极高的带宽和纳秒级延迟。然而,其连接范围受限,无法作为接口直接连接外部的QPU控制器和经典加速计算节点;InfiniBand作为一种行业标准网络协议,主要用于连接跨集群和数据中心的多台服务器(节点间通信),强调大规模横向扩展。虽然其延迟较低(通常在微秒量级),但对于需要亚微秒或单微秒反馈的QEC循环来说,其延迟仍显得过高,无法保证容错操作的确定性。
NVQLink的诞生正是为了提供QEC所需的“极度苛刻的低延迟、高吞吐连接”。基于其前身架构DGX Quantum与Quantum Machines OPX控制平台的集成经验,NVQLink实现了关键的性能指标:控制器-GPU数据往返延迟小于4微秒。
这一小于4微秒的延迟指标被视为实用化容错计算的“准入门槛”。对于许多超导和离子阱Qubit而言,其相干时间在几十到上百微秒不等,QEC循环必须远快于此以有效保护逻辑比特。4微秒的经典计算往返延迟使得QEC循环能够稳定、快速地迭代。该设计直接针对量子比特的物理约束,而非单纯追求理论上的数据吞吐量。
 来源:NVIDIA
来源:NVIDIA通过NVQLink开放架构,NVIDIA能够利用其强大的GPU计算能力,承担原本需要专用硬件才能完成的实时控制任务。例如,Alice & Bob等公司正利用NVQLink进行逻辑编排、解码和实时校准。将QEC任务转移到高并行度的GPU上,可以有效降低定制硬件的成本和开发周期,极大地加速了FTQC的工程化和产业化。
新链路的低延迟与高吞吐
此次的NVQLink可以说是在NVLink高速、低延迟互联技术理念上的进一步升级。在NVQLink正式推出之前,NVIDIA DGX Quantum系统已作为第一个将量子控制器直接连接到NVIDIA加速计算堆栈的系统,验证了微妙级延迟集成的技术可行性。NVQLink在此基础上发展成为一个开放标准,同时允许现有DGX Quantum用户无需硬件更改即可升级,利用新的CUDA-Q能力和增强的实时性能。
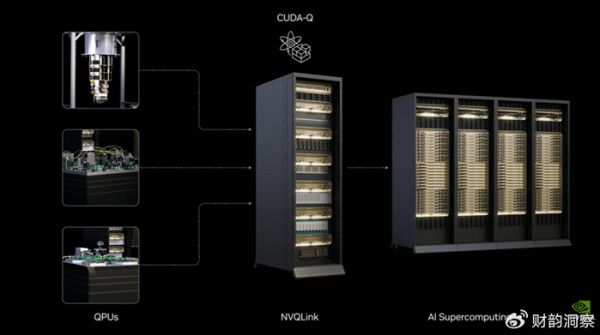 来源:NVIDIA
来源:NVIDIA因此,NVQLink并非孤立的硬件接口,它与NVIDIA的CUDA-Q平台深度集成。CUDA-Q旨在提供一个统一的开发环境,允许开发者无缝地同时编排QPU、GPU和CPU资源。
在软件层面,NVQLink在DGX Quantum的基础上增加了新的设备调用和API层,允许QPU开发者利用GPU进行高效控制。这种集成使得QPU能够与AI超级计算机进行实时数据交换和控制。例如,Quantum Machines演示了在CUDA-Q平台上,一个完整的QEC循环,包括测量量子比特、数据传输到GPU、经典计算并将结果返回都可以在一个可执行文件中完成。此外,Infleqtion等合作伙伴也将其Superstaq编译器与CUDA-Q工具链集成,以实现优化的编排,并简化对NVQLink硬件的调用。
NVIDIA量子总经理Tim Costa表示:“NVQLink架构将量子处理器和控制系统与NVIDIA AI超级计算相结合,提供了一个强大的平台,使构建者能够克服集成和扩展量子硬件的挑战。“
NVQLink的生态系统构成
正如前文提到,NVQLink的战略成功很大程度上源于其开放性和广泛的生态系统支持。该架构的开发得到了9家美国国家实验室和17家QPU厂商以及5家量子控制系统构建商的支持。

这意味着NVQLink正在成为异构量子硬件的通用互联语言,成功覆盖了多种主要的QPU模态,从Pasqal的中性原子到IQM的超导再到Alice&Bob的猫量子比特,NVQLink在经典控制和加速计算之间建立高速管道,使得开发者可以将精力集中于QEC算法本身,而不是为每种QPU设计不同的加速接口。这种兼容性极大地推动了行业标准化和软件可移植性。
如果主流QPU厂商都采用NVQLink和CUDA-Q,那么其他试图进入量子加速领域的竞争者将面临巨大的兼容性壁垒。这种强大的生态绑定也使得NVIDIA在混合量子-经典架构中占据了不可动摇的中心地位,即使不生产QPU,也成为了FTQC的“中枢神经系统”。
NVQLink与中美科技生态的巨大分野:计算生态VS物理生态
当我们为NVQLink的微秒级延迟和开放生态鼓掌时,这场发布会所揭示的,早已超越了一款新硬件接口的技术范畴,它代表了美国在未来计算基础设施上的战略性、体系性胜利,并将中美两国的科技文明水平推向了一个前所未有的分野。
英伟达所做的是什么?它不是简单地制造了一个量子纠错系统,而是在AI超级计算(GPU)已经铸就全球霸权的基础上,主动搭建起一座通往容错通用量子计算(FTQC)时代的桥梁。NVQLink和CUDA-Q的出现,意味着美国正在完成“量子基础设施”的工程化和标准化,将量子计算从实验室的“科学奇迹”收编为数据中心的“可控加速器”。这种通过GPU核心优势反向整合下一代计算生态的能力,展现了美国科技巨头在全球产业链中最顶层的设计权和定义权。
美国量子计算的领头羊或者核心中枢,是英伟达、IBM和谷歌这些计算机巨头,他们已超越“硬件供应商”或“软件服务商”的单一角色,成为量子科技产业思维的引领者与生态价值的构建者。它们通过构建量子科技的产业逻辑、整合全球资源、打通技术-场景链路,正在全球范围内定义量子科技产业的竞争规则。
 图:经典-量子混合计算生态来源:光子盒研究院
图:经典-量子混合计算生态来源:光子盒研究院英伟达、IBM和谷歌的产业思维与生态价值,通过“技术溢出、基建填补、标准定义”,推动量子科技产业从“单点创新”走向 “系统创新”,从“线性增长” 走向 “指数级跃迁”。
这种思维与价值的革新,不仅是量子科技企业自身竞争力的核心,更是国家量子科技竞争力的关键——美国通过英伟达、IBM和谷歌等巨头的生态优势,维持全球技术标准主导权,这在不就的将来将直接决定全球量子科技产业的竞争格局与发展方向。
美国这种“计算生态”的思维是量子计算技术突破与应用落地的正确道理,这是美国在过去70年引领全球IT技术与产业发展的法宝。中国目前是一种“物理生态”,物理学家们在推动量子计算技术的发展,生态无从谈起,计算巨头集体缺位,量子计算本质是“计算”,没有计算机学科的人才,包括AI人才的广泛参与,中国的量子计算技术难以追赶,产业主导权更有可能拱手想让。
NVQLink所丈量的,不仅仅是4微秒的延迟,更是中美两国在高科技生态位上的巨大时间差。美国正在稳步踏上“FTQC文明”的阶梯,将AI与量子深度融合,抢占下一个十年的制高点。而中国,如果不能迅速在底层基础设施,尤其是GPU和统一互联标准上迎头赶上,这种结构性的差距将不再是“落后”,而是一种文明等级的降维打击,使得我们不得不长期仰视大洋彼岸所定义的未来。
这场竞赛的终点,是决定谁将主导下一代科学发现和产业变革的权力,我们必须高度美国生态建设带来的启示,认识到问题的严重性。
(文章来自《光子盒》)
发布于:北京
相关推荐
不要再看英伟达的热闹了!中国的量子计算正被美国快速甩开
华尔街热炒量子计算股,但谷歌的量子芯片实际上并不具备计算能力
美国将对H20出口管制和英伟达的“B20+GB20”替代方案
量子计算,正处于一个深刻转变之中
IBM、AMD共创“下一代计算架构” 推动量子计算几年内走上台面
谁能成为中国的英伟达?
大模型热到芯片暴涨,阿里百度成了英伟达的打工仔
被美国打压一年后,“中国英伟达”干了票大的
一文读懂:有关量子计算的十个问题
“俄罗斯蔑视美国制裁,计划使用被禁的英伟达H100制造超算”
网址: 不要再看英伟达的热闹了!中国的量子计算正被美国快速甩开 http://www.xishuta.com/newsview143703.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



