前谷歌研究员发文:算力崇拜时代该结束了
(来源:机器之心)
机器之心编辑部
过去十年,我们几乎把 AI 领域的创新简化成一条公式:更多参数、更多数据、更多算力。可未来的突破,是否仍然只能从训练算力中产生,其实并不清楚。
这个问题之所以重要,是因为「算力驱动进步」的信念,已经深刻改变了整个领域的研究文化。学术界因缺乏算力逐渐被边缘化,研究参与在地域上高度集中;巨额资本投入也让原本开放的发表传统变得愈发封闭。
在过去的一段时间,前谷歌大脑研究员、Cohere 前 AI 研究负责人 Sara Hooker 一直在呼吁大家重视这个问题。最近,她还把自己之前的演讲内容写成了文章。

文章标题:On the slow death of scaling.
文章链接:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5877662
文章中提到,对于深度神经网络而言,持续扩展训练计算资源效率极低。我们花费大量资源来学习那些低频特征的长尾部分,而所有迹象都表明,我们正处于收益递减的时期。在模型规模不再逐年翻倍的世界里,模型如何从环境中学习并有效地从新知识中适应,就显得尤为重要。在文章中,她探讨了一些未来有价值的方向。
以下是文章内容节选。
一个不容忽视的趋势:小模型的崛起
声称 scaling 正在走向终结,这在许多领域都存在争议。因为过去十年的所有证据都表明,扩展计算能力能够解锁更大的模型规模或数据集。增加计算能力也恰好符合行业季度规划的节奏,相比提出一种替代的优化技术,提议训练更大的模型风险更小。
但仅仅依靠计算资源会忽略规模与性能之间的关系正在发生的一个关键转变。更大的模型并不总能带来更好的性能。最近几年出现了很多大模型被规模小得多的小模型超越的案例。如下图 3b 所示,随着时间推移,这类小模型数量激增。
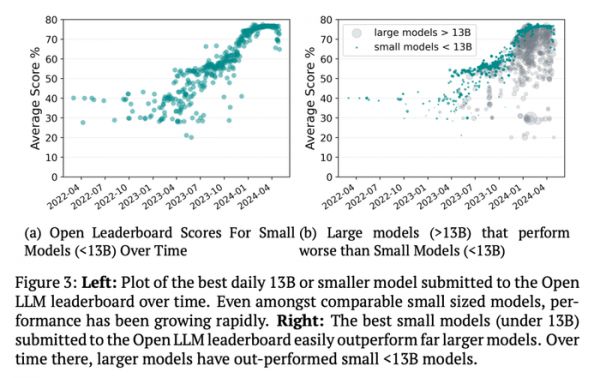
要理解为什么会出现这种情况,我们必须弄清楚在过去十年中,哪些关键变量一直在推动性能的提升。在计算资源回报递减的时代,优化和架构上的突破决定了单位计算资源的回报率。而正是这种回报率,对发展速度以及额外计算资源所带来的风险水平最为关键。
哪些因素会影响算力回报率?
在复杂系统中,孤立地操控一个变量并预见所有影响是极具挑战性的,人们对计算量的推崇也是如此。
增大模型规模正面临收益递减
过去十年,模型参数量从早期 Inception 的 2300 万暴增至 Qwen3-235B 的 2350 亿。尽管更大模型确实带来了性能提升,但额外的参数数量与泛化能力之间的关系仍不清楚。
令人困惑的是:训练结束后,我们可以删除大部分权重而几乎不损失性能;但若一开始就不启用这些权重,则无法达到相同效果。研究发现,仅用一小部分权重就能预测网络中 95% 的权重,说明存在大量冗余。这可能反映的是深度学习技术本身的低效 —— 如果有更好的学习方法,我们可能根本不需要这么大的网络。
增大模型规模是学习长尾分布的一种成本极高的方式。深度神经网络的学习效率极低。它们能快速学会常见特征,却需要大量算力和时间来学习罕见特征。这是因为训练基于平均误差最小化,所有样本被同等对待,导致低频特征的信号在批量更新中被稀释。而现实世界中,大多数属性恰恰是低频的 —— 人类智能的独特之处正是能高效处理这类长尾数据。深度网络在这方面最为吃力,训练的大部分算力都被消耗在以极高代价记忆长尾数据上,如同「搭梯子登月」般低效。
数据质量降低了对计算资源的依赖
在质量更高的数据上训练的模型不需要那么多计算资源。大量研究表明,改进训练语料库的一些工作,包括去重、数据修剪或数据优先级排序,可以弥补模型规模的不足。这表明,可学习参数的数量并非提升性能的绝对限制因素;对更高数据质量的投入能够减少对更多(计算资源等)的需求。
新的算法技术弥补了计算量的不足
过去几年的进展,既得益于算法的改进,也得益于计算能力的提升。这包括通过指令微调扩展预训练,以教会模型遵循指令;利用更大、性能更强的「教师」模型生成的合成数据进行模型蒸馏,来训练能力强、规模小的「学生」模型;思维链推理;增加上下文长度;检索增强生成;以及通过偏好训练使模型与人类反馈保持一致等。
所有这些技术都弥补了对大量权重或昂贵的长时间训练的需求。在所有条件相同的情况下,与未使用这些优化技巧且在相同计算量下训练的模型相比,这些技术已被证明能显著提升模型性能。我们正用相同数量的资源做着多得多的事情。
架构在决定可扩展性方面起着重要作用
架构在确定单位计算量下的整体性能回报率方面起着巨大作用。它在决定进步上限方面也至关重要。新架构设计的引入可以从根本上改变计算量与性能之间的关系,并使任何现有的 scaling law 变得无关紧要。
Scaling Law 的局限性
巴菲特曾说过一句话:「别问理发师你需不需要理发。」同样的道理,也别去问计算机科学家或经济学家能不能预测未来。人们往往会被「我能预测」的诱惑牵着走,而忽视了对预测边界应有的谦逊。关于模型规模与性能关系的 scaling law 正是这种自信膨胀的体现。它试图用算力规模去推断预训练损失的变化,或预测下游能力如何随规模出现,但现实远比公式复杂。
Scaling Law 之所以流行,很大程度上源于人们过度相信算力是推动进步的核心变量。它逐渐成了一个万能说法,被用来为巨额投资甚至政策决策背书。其吸引力也不难理解,如果能力真的能随算力精确预测,资本配置就会显得异常清晰。但问题在于,我们几乎从未准确预测过性能究竟会提升多少,这让「算力投入的回报率」在科学上难以站得住脚。
更关键的是,Scaling Law 真正被反复验证的,只是对预训练测试损失的预测,也就是模型补全文本的能力。一旦换成真实的下游任务表现,结果往往混乱且不一致。所谓的「涌现能力」,常被用来解释这种落差,看似是能力突然出现,实际上等于承认 Scaling Law 并不能告诉我们未来会发生什么。即便只预测测试损失,在数据分布假设略有变化时,结果的可复现性也会出现问题。越来越多研究发现,许多能力的提升曲线并不平滑,甚至根本不符合幂律。
对于需要向未来外推的复杂系统来说,小误差会不断累积,而样本数量又极其有限。每一个数据点都是一整个模型,高昂的计算成本意味着很多 scaling 结论建立在不到百个样本之上,统计支撑本身就很脆弱。因此,不同领域中 Scaling Law 的可靠性差异巨大。比如代码生成在极大算力跨度内表现出相对稳定的幂律关系,而其他能力则显得更加不可预测。
在架构、优化方法和数据质量保持不变的短期受控环境下,Scaling Law 对规划训练规模仍有一定价值。但一旦拉长时间尺度,它们就很难经得起检验。Scaling Law 的频繁失效提醒我们,单纯堆算力并不是一条直线式的进步路径。那些过度依赖 Scaling Law 的前沿 AI 公司,可能正在低估其他创新方向的价值,而真正的突破,往往正藏在这些被忽视的地方。
未来前进方向
在计算机科学中,我们长期把算力当成银弹。
但现实正在发生分化。一方面,至少在短期内,人们仍会继续把模型做得更大,试图从逐渐老化的架构中榨取最后的性能;另一方面,算力与性能之间的关系却越来越紧绷,也越来越难以预测。单纯依赖算力,正在变成一条不稳定的道路。
真正有可能引领下一轮创新的前沿实验室,不会把赌注只压在算力上。更有价值的进展,来自对优化空间的根本性重塑,也就是范式层面的转变。与以往不同的是,计算机科学家如今需要同时优化的「工具箱」大幅扩展,这不仅会决定他们把时间花在哪里,也会影响「发现」本身是如何发生的。
新的优化空间
如今,越来越多的计算并不是花在训练阶段,而是花在训练之外、推理之中。过去,模型性能的提升几乎等同于更多数据、更长训练或更大参数规模,而现在,一个明显的转向正在发生:通过在推理时投入更多算力,用搜索、工具调用、多智能体协作或自适应计算来提升表现,而不必改动模型本身。更重要的是,这些方法大多不依赖梯度更新,彻底偏离了过去三十年以训练为中心的进步路径。已有研究表明,仅靠推理阶段的计算放大,就可能带来数倍甚至一个数量级的性能提升,而所需算力远低于重新预训练的成本。

与此同时,数据也不再是不可触碰的「静态背景」。长期以来,高质量标注数据稀缺且昂贵,训练集往往被视为对世界的固定快照,从 MNIST、ImageNet 到 SQuAD,AI 的进步建立在这些冻结的数据之上。但现实使用中,模型最擅长的始终是训练分布,而推理时真正重要的场景却常常数据不足,训练与使用之间由此产生结构性错位。随着合成数据成本大幅下降,数据空间本身开始变得可塑,我们可以有意识地生成、引导和放大那些原本稀少却关键的分布区域,这也动摇了机器学习中关于 IID 样本的基础假设。
最后,智能系统的核心正在从「更强的模型」转向「更会与世界互动的系统」。算法本身不再是全部,交互方式、界面设计以及多组件系统的协同,正在成为决定智能上限的重要因素。曾经属于 UX 或人机交互的小众问题,正在走到计算机科学研究的正中央。
只要还用 Transformer,scaling 就会变得没有意义
在以 Transformer 为核心架构的前提下,只要我们仍局限于 Transformer 这种架构,继续扩大计算规模就没有意义。现有架构已经明显出现边际收益递减,再投入算力也难以换来成比例的进步。深度神经网络主导了过去十年的发展,但越来越多迹象表明,下一次真正的跃迁需要一种全新的架构。随着模型开始持续与世界互动,如何避免灾难性遗忘成为关键挑战,而依赖全局参数更新的深度网络,在持续学习和知识分化上先天受限,很难像大脑那样形成相对独立、可专门化的知识区域。
与此同时,训练算力「scaling 退潮」并不等于 AI 的环境影响会随之减轻。需要区分的是,算力与性能关系的变化,并不等同于整个 AI 系统的计算开销下降。即便模型本身变得更小、更高效,AI 也会被部署到越来越多的场景中。真正的能耗大头,往往不在训练,而在模型上线后的生产化与大规模服务阶段。当数十亿用户同时使用 AI 时,即使单个模型更轻量,总体能耗仍可能持续上升,这依然是一个不容忽视的现实问题。
相关推荐
DeepSeek算力需求暴降,为什么全球算力竞赛反而更疯狂了?
阿里进入大模型时代,核心是算力和生态
AI算力光速革命
OpenAI走向“算力帝国”
DeepSeek将拉低算力总需求?美国科技四巨头今年算力投资不减
硅谷新公司SF Compute,AI算力的“Airbnb”
V3.2逼近Gemini 3,DeepSeek硬气喊话:接下来我要堆算力了
人类最强算力来临,谷歌的「量子霸权」霸道在哪?
我国算力服务体系该如何构建?
全球90%的算力,掌握在美国手中,没有算力,我们该怎么办?
网址: 前谷歌研究员发文:算力崇拜时代该结束了 http://www.xishuta.com/newsview146001.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



