非监督强化学习Get新技能:谷歌DADS算法助力智能体实现多样化行为发现
编者按:本文来自微信公众号“将门创投”(ID:thejiangmen),36氪经授权发布。
From:Google
编译:T.R
近年来强化学习的高速发展已经证明监督强化学习可以在真实世界中处理包括任意物体的抓取、灵巧的运动等复杂的任务。然而利用精心设计的奖励函数来教会智能体进行复杂的行为却面临着显著的局限性。
一方面在设计损失函数上需要大量的工程性工作,对于大量任务来说几乎是不可能的。另一方面针对真实环境设计奖励,其复杂性不仅来自于奖励函数本身,同时还需要一系列的环境基础设施(额外的传感器)或手工标注的目标状态来进行辅助。这种奖励函数工程方式显示了智能体学习复杂行为的过程,而无监督学习的出现为这一问题提供了潜在的解决思路。
在监督强化学习中,来自环境的外部奖励将引导智能体学习期待的行为,强化对环境进行期待的行为改造。而在非监督强化学习中,整体则利用内在的奖励函数(例如尝试环境中不同事物的好奇心)来生成训练信号,从而可以获得更为广泛的任务无关的技能行为。
内部奖励函数可以绕过外部奖励函数特有的工程问题,在无需额外设计的情况下适用于更广泛更通用的任务上去。虽然已经有很多研究人员聚焦于实现非监督强化学习的不同手段,但这是一个严重欠约束的问题,没有环境奖励函数的引导是很难学习到有用的行为的。那么主体和环境间交互的有效特性是否可以帮助发现更好的行为(技能)呢?
这篇文章中将介绍关于非监督强化学习的最新研究。在DADS(Dynamics-Aware Unsupervised Discovery of Skills)方法中为非监督学习引入了可预测的优化目标,将技能的基础特性视为可以对环境带来可预测的改变,基于这一观点开发出了非监督强化学习技能发现算法,并在模拟实验中展示了其广泛适应性。随后研究人员还改进了样本效率,展示了非监督技能发现对于真实世界的可行性。

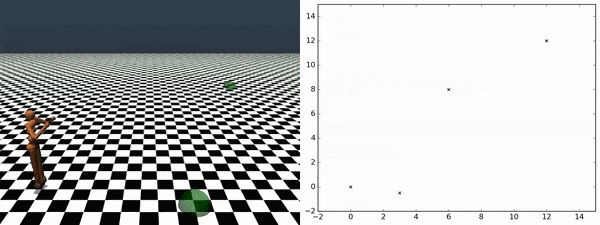
左图表示随机不可预测的行为,右图描述了在可预测环境中的系统性运动。本研究的目标在于学习像右图一样潜在的有用行为而无需奖励函数工程。DADS概览
DADS设计了一个内部奖励函数来鼓励主体发现可预测、多样性的技能。在以下两种情况下内部奖励函数值很高:
(a).不同技能对于环境的改变不同(鼓励多样性);
(b).给定技能在环境的造成的改变是可预测的(可预测性)。由于DADS无法从环境中获取任何奖励,技能优化的多样性可以使得智能体抓住尽可能多的潜在有效行为。
为了判断技能是否具有可预测性,文章中又训练技能动力学网络,在给定当前状态和执行技能后来预测环境状态的改变。技能动力学网络对于环境状态的预测越好,对于技能就越是可预测的。DADS定义的内部奖励可以利用任何传统的强化学习算法来最大化。

DADS的概览图
这套算法使得多个不同的主体可以通过与环境纯粹的无奖励交互来发现可预测的技能。DADS与先前的算法不同,可以拓展到高维度的连续控制环境中,例如人形机器人、模拟双足机器人等。由于DADS可适应多种环境,可用于在方向性的环境中定位、操控和运动。下图展示了一些实验中的例子。

旋转跳跃、人形仿真的不同步态、旋转目标的不同方法。利用模型动力学实现基于模型的控制
DADS不仅可以发现可预测的潜在有用模型,同时允许高效地将学习到的技能应用于下游任务中去。DADS可以利用学习到的技能动力学来预测每个技能的状态转移,预测的状态转移可以被衔接起来模拟任意技能的完整状态轨迹,而无需在环境中执行。因此我们可以模拟不同技能的轨迹,并为给定的任务选择最高奖励的技能。基于模型的规划方法具有很高的样本效率并无需额外的训练。相较于先前的方法是一个重要的进步,无需针对学习到的技能在环境中进行额外的训练。
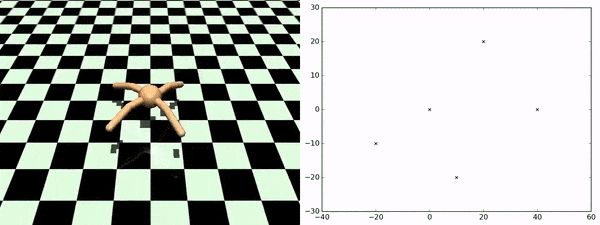
利用智能体发现的技能,就可以在无需额外实验的情况下遍历任意检查点。上图显示了主体在检查点间的遍历情况。真实实验
为了验证算法的有效性,研究人员针对这一算法提出了简化版本off-DADS,通过离线学习对算法和系统上的改进,使得模型可以利用从不同策略下收集的数据来改进当前策略。特别是对于先前数据的复用将显著提升强化学习算法的样本效率。在改进的离线策略基础上,研究人员从随机初始化策略开始训练了小四足机器人,在没有任何环境奖励和手工探索策略的情况下,通过DADS定义的内部奖励实现了多种步态和方向性运动。


这种新颖的非监督学习技能发现方法可以在将来被用于更为广泛的真实世界任务中,在最小化人类工作的情况下适应广泛场景和任务需求。未来研究人员们将在状态表示和技能发现间进行更为深入的研究,并探索将高级的运动规划和底层的控制进行分离的技能探索策略。如果想要了解详细信息,请参看论文和代码:
https://arxiv.org/pdf/2004.12974.pdfhttps://arxiv.org/pdf/1907.01657.pdfhttps://github.com/google-research/dads
相关推荐
非监督强化学习Get新技能:谷歌DADS算法助力智能体实现多样化行为发现
霸榜马里奥赛车,谷歌将神经进化引入自解释智能体,强化学习训练参数锐减1000倍
NeurIPS多智能体强化学习竞赛夺冠的背后,是决策智能公司「启元世界」
当AI开始“踢脏球”,你还敢信任强化学习吗?
机器学习圣杯:图灵奖得主Bengio和LeCun称自监督学习可使AI达到人类智力水平
像FIFA一样踢球的AI,比打游戏更强吗?
算法耗尽全球GPU算力都实现不了,DeepMind阿尔法系列被华为怒怼,曾登Nature子刊
2018全球智能媒体研究综述
别光顾着看支付宝年度账单,AI在公共安全领域的这份2019发展清单你Get了吗?
我们深挖后发现,谷歌申请的AI专利何止一个Dropout
网址: 非监督强化学习Get新技能:谷歌DADS算法助力智能体实现多样化行为发现 http://www.xishuta.com/newsview24328.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



