从苹果A14芯片看AI算力的新摩尔定律
本文来自微信公众号:半导体行业观察(ID:icbank),作者:李飞,题图来自:视觉中国
最近苹果在发布会上公开了新的A14 SoC。根据发布会,该SoC将用于新的iPad上,而根据行业人士的推测该SoC也将会用在新的iPhone系列中。除了常规的CPU和GPU升级之外,A14最引人注目的就是Neural Engine的算力提升。我们认为,苹果A系列SoC在近几年内Neural Engine的算力增长可以作为一种新的AI算力范式,成为新的摩尔定律。
A14上的新Neural Engine
苹果公布的A14 SoC使用5nm工艺,而新的Neural Engine则使用16核心设计,其峰值算力可达11 TOPS,远超上一代的Neural Engine(6TOPS)。在发布会上,苹果明确表示该Neural Engine主要支持加速矩阵相乘。此外,苹果还表示新的Neural Engine结合CPU上的机器学习加速,可以将实际的AI应用体验相对于前代提升十倍。
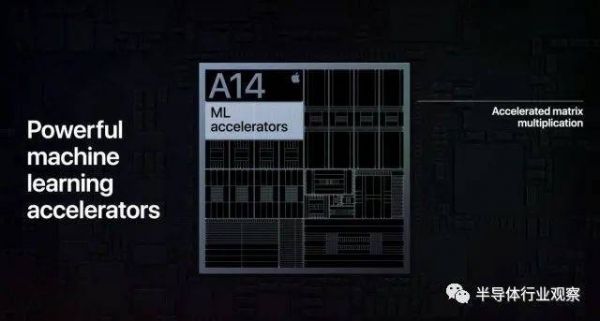
新的Neural Engine的峰值算力大大提升可以说是有些意料之外,但是又是情理之中。意料之外是因为A14的其它关键指标,例如CPU和GPU等相对于前一代A13的提升并不多(发布会上给出的30%提升对比的是再前一代的A12 SoC,如果直接和上一代A13相比则CPU性能提升是16%而GPU则是10%左右),但是Neural Engine的性能提升则接近100%。而Neural Engine性能提升大大超过SoC其他部分是情理之中则是因为我们认为如果仔细分析SoC性能提升背后的推动力,则可以得出Neural Engine性能大幅提升是非常合理的。
一方面,从应用需求侧来说,对应CPU和GPU的相关应用,例如游戏、网页浏览、视频等在未来可预见的几年内都没有快速的需求增长,唯有人工智能有这样的需求。另一方面,CPU和GPU的性能在给定架构下的性能提升也较困难,很大一部分提升必须靠半导体工艺,而事实上半导体工艺的升级在未来几年内可预期将会越来越慢,每代工艺升级更注重于晶体管密度以及功耗,在晶体管性能方面的提升将越来越小。而AI加速器则还有相当大的设计提升空间,相信在未来几年仍将会有算力快速增长。
Neural Engine算力增长趋势
我们不妨回顾一下过去几代A系列SoC中Neural Engine的算力增长。

最早加入Neural Engine的SoC是2017年发布的A11。该SoC使用10nm工艺,搭载第一代Neural Engine峰值算力为0.6TOPS,Neural Engine的芯片面积为1.83mm2。当时Neural Engine主要针对的应用是iPhone新推出的人脸识别锁屏FaceID以及人脸关键点追踪Animoji,且Neural Engine的算力并不对第三方应用开放。
第二代Neural Engine则是在2018年的A12 SoC上。该SoC使用7nm工艺,Neural Engine面积为5.8mm2,而其峰值算力则达到了5TOPS,相比前一代的Neural Engine翻了近10倍。而根据7nm和10nm工艺的晶体管密度折算则可以估计出Neural Engine的晶体管数量大约也是增加了6-7倍,基本和算力提升接近。
第三代Neural Engine是2019年的A13,使用第二代N7工艺,其面积相比上一代减少到了4.64mm2,而算力则增加到了6TOPS。我们认为这一代的Neural Engine是上一代的小幅改良版本,并没有做大幅升级。
最近公布的A14则搭载了最新一代的Neural Engine,使用5nm工艺,Neural Engine的具体面积尚没有具体数字,但是其算力则是达到了11TOPS,是上一代的接近两倍。
从上面的分析可以看出Neural Engine每次主要升级都伴随着算力的大幅上升,第一次上升了近十倍,而第二次则上升了近两倍。如果按照目前两年一次主要升级的节奏,我们认为在未来数年内Neural Engine乃至于广义的AI芯片市场都会有每两年性能提升两倍的规律,类似半导体的摩尔定律。我们认为,这样的规律可以认为是AI芯片算力的新摩尔定律。
为什么AI芯片算力增长会成为新的摩尔定律
AI芯片算力指数上升的主要驱动力还是主流应用对于AI的越来越倚重,以及AI神经网络模型对于算力需求的快速提升。
应用侧对于AI的需求正在越来越强。就拿智能设备为例,2017年苹果A11中AI的主要应用还是面部关键点识别和追踪,而到了2018年开始越来越多的应用开始使用AI,包括图像增强、拍摄虚化效果等,在下一代智能设备中AI则更加普及,首先从人机交互来看,下一代智能设备中常见的人机交互方式手势追踪、眼动追踪、语音输入等都需要AI,这就大大增加了AI算法的运行频率以及算力需求。
此外,下一代智能设备中有可能会用到的一系列新应用都倚重AI,包括游戏、增强现实等应用中,都需要运行大量的AI模型例如SLAM,关键点识别、物体检测和追踪、姿势识别和追踪等等。
另一方面,AI对于算力的需求也在快速提升。根据HOT CHIPS 2020上的特邀演讲,AI模型每年对于算力需求的提升在10倍左右,因此可以说AI模型对于硬件加速的需求非常强。
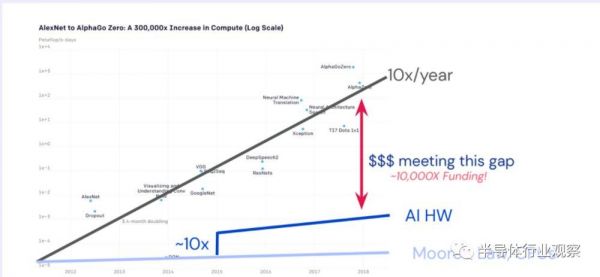
如果我们从另一个角度考虑,这其实就意味着AI加速芯片的算力提升在赋能新的场景和应用——因为总是有新的性能更高的AI模型需要更强的硬件去支持,而一旦支持了这样的新模型则又能赋能新的应用。
从目前主流的计算机视觉相关的AI,到以BERT为代表的大规模自然语言处理算法,以及未来可能出现的将BERT和计算机视觉相结合的视觉高阶语义理解等等,我们在未来几年内尚未看到AI模型进步的停止以及可能的新应用场景的出现,相反目前的瓶颈是AI加速硬件性能跟不上。
这也就意味着,AI加速硬件才是AI模型落地的最终赋能者,这就像当年摩尔定律大跃进的PC时代,当时每一次CPU处理器的进步都意味着PC上能运行更多的应用,因此我们看到了CPU性能在当时的突飞猛进;今天这一幕又重现了,只是今天的主角换成了AI加速芯片。
AI算力增长来自何方?
分析完了AI加速芯片的需求侧,我们不妨再来看看供给侧——即目前的技术还能支持AI芯片多少算力提升?
首先,AI加速器芯片和传统CPU的一个核心差异在于,CPU要处理的通用程序中往往很大一部分难以并行化,因此即使增加CPU的核心数量,其性能的增加与核心数也并非线性关系;而AI模型的计算通常较为规整,且很容易就可以做并行化处理,因此其算力提升往往与计算单元数量呈接近线性的关系。这在我们之前对比A11和A12 Neural Engine的晶体管数量和算力提升之间的关系也有类似的结论。
目前,以Neural Engine为代表的AI加速器占芯片总面积约为5%,未来如果AI加速器的面积能和GPU有类似的面积(20%左右),则AI加速器的计算单元数量也即算力至少还有4倍的提升空间。此外,如果考虑两年两倍的节奏并考虑未来几年内可能会落地的3nm工艺,则我们认为AI加速器算力两年两倍的提升速度从这方面至少还有5-6年的空间可挖。
除了单纯增加计算单元数目之外,另一个AI加速器算力重要的提升空间来自于算法和芯片的协同设计。从算法层面,目前主流的移动端模型使用的是8-bit计算精度,而在学术界已经有许多对于4-bit甚至1-bit计算的研究都取得了大幅降低计算量和参数量的同时几乎不降低模型精度。
另外,模型的稀疏化处理也是一个重要的方向,目前许多模型经过稀疏化处理可以降低50%~70%的等效计算量而不降低精度。因此如果考虑模型和芯片和协同设计并在加速器中加入相关的支持(如低精度计算和稀疏化计算),我们预计还能在计算单元之外额外带来至少10倍等效算力提升。
最后,当峰值算力的潜力已经被充分挖掘之后,还有一个潜力方向是针对不同AI模型的专用化设计,也即异构设计。AI模型中,常用于机器视觉的卷积神经网络和常用于机器翻译/语音识别的循环卷积网络无论是在计算方法还是内存访问等方面都大相径庭,因此如果能做专用化设计,则有可能在峰值算力不变的情况下,实际的计算速度仍然取得数倍的提升。
结合上面讨论的一些方向,我们认为AI加速芯片的算力在未来至少还有数十倍甚至上百倍的提升空间,再结合之前讨论的应用侧对于算力的强烈需求,我们认为在未来数年内都会看到AI加速芯片的算力一两年翻倍地指数上升。在这一领域,事实上中国的半导体行业有很大的机会。如前所述,AI芯片性能提升主要来自于设计的提升而非工艺提升,而中国无论是在半导体电路设计领域还是AI模型领域都并不落后,因此有机会能抓住这个机会。
本文来自微信公众号:半导体行业观察(ID:icbank),作者:李飞
相关推荐
从苹果A14芯片看AI算力的新摩尔定律
苹果A系列芯片的三年AI进化:为何要大规模升级AI算力?
从算力、数据、算法、工程化等维度看AI的未来
新基建的背后,是一场算力之争
探索摩尔定律之外的新路径,「登临科技」将GPU通用计算芯片功效提高3倍以上
A14处理器性能明显提升,苹果何时可以自研5G芯片?
从联想到比特大陆,中国的算力芯片之路
苹果、华为、三星……5nm芯片之争谁是最大赢家?
AI算力报告:未来五年,AI芯片复合增⻓率将达到53%
移动芯片如何走出“高水平均衡陷阱”?
网址: 从苹果A14芯片看AI算力的新摩尔定律 http://www.xishuta.com/newsview31346.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



