著名分析师 Benedict Evans:人脸识别与AI伦理(一)
神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:对于人脸识别来说,不同的地方监管政策是不一样的。显然,欧盟这地方要严格很多,而我们这里似乎就没那么多的顾虑。究竟应该如何看待这项技术,又应该如何进行监管。A16Z知名VC Benedict Evans提出了自己的看法。原文标题是:Face recognition and the ethics of AI。36kr进行了编译,分两部分刊出,此为第一部分。

胡安•格里斯,《咖啡馆里的男子》
著名分析师 Benedict Evans:人脸识别与AI伦理(二)
我们对脸部识别的担忧就像对数据库的担忧一样——我们担心里面含有不好的数据会怎么样,我们担心会被坏人利用。
我们对这个问题的看法容易陷入二元论。但其实这里面有很大一块的灰色地带,我们还没有就什么是“不好”达成明确共识,也不知道我们是不是担心过头,因为这不仅仅是新的,我们不熟悉的东西,而且因为那是不一样的东西。
跟机器学习很像,脸部识别识别正迅速成为很多人都可以并也会用于开发各种东西的商品化技术。“人工智能伦理”委员会也许可以顶一下子,但不会是完整的解决方案,而且监管(会采取多种形式)会更进一步。但中国公司有自己的道德委员会,并且已经出口他们的产品。
早在20世纪70、80年代初时,科技行业就创造出了一种变革性的新技术,为政府和企业提供了前所未有的跟踪,分析和理解我们所有人的能力。关系数据库意味着在理论上小范围内有可能的事情第一次变得在实际上具有大规模的可能性。大家都很担心这个问题,并且写了很多这方面的书。

很多书都表达了对数据库的担忧
具体来说,我们担心这两种问题:
我们担心这些数据库会包含不良数据或错误假设,尤其是它们可能会无意间把我们社会存在的成见和偏见编码进机器里面。我们担心大家会把事情搞砸。
而且,我们担心大家会故意开发和利用这些系统来做坏事。
也就是说,我们担心如果这些系统不能正常工作会怎么样,我们也担心如果它们能够正常工作的话又会怎样。
我们现在就AI(或更恰当地说是机器学习)展开的对话大致也是这样,尤其是因为有了机器学习才成为可能的人脸识别的问题。而且,我们在担心同样的事情——我们担心如果它不起作用会怎么样,我们担心如果它起作用又会怎样。我想,我们也在尝试着弄清楚这个在多大程度上属于新问题,我们对它的担心有多少,以及为什么我们要担心。
首先,“当大家把事情搞砸了”。
当好人用了不良数据时
大家对数据库的看法错了。我们大概都听说过关于税局不同版本的老笑话,说的是他们把你名字写错了之后让你改名字还容易过改正那个错误。还有一个完全不是笑话的问题,那就是你跟通缉犯同名,然后总是被警察拦住,或者你的名字跟恐怖分子的一样,然后被列入了禁飞名单或者更糟。还有一件事,今年春天,一名安全研究人员声称自己注册了“NULL”作为自定义的驾照地址,结果现在收到了数百张乱停车的罚单。
这些故事说明了三个不同的问题:
系统可能包含不良数据(名字拼写错误)......
或者有bug或者对其如何处理有错误假设(无法将“Null”当作名称处理,或“Scunthorpe”触发猥亵过滤器)
还有,系统被未经培训、不按流程、缺乏体制结构或者授权的人处理,所以没有意识到错误的出现并作出相应处理。
当然,所有的官僚体制都会受到这一系列问题的影响,这可以追溯到在第一张穿孔卡片诞生的几千年前。数据库用不同的尺度为我们提供了该问题新的表达方式,现在的机器学习也是这样。但是ML(机器学习)引入了各种不同的搞砸方式,而这些都是其自身运作方式所固有的问题。
比方说:假设你想要一套可识别猫照片的软件系统。旧的做法是建立一系列逻辑步骤——先开发出能检测边缘的东西,然后开发能检测尖耳朵的东西,以及眼睛检测器,一个腿部计数器等......这样下来最终需要几百个步骤,而且做得总是不如人意。的确,这就像想造机械马一样——理论上完全可能,但实际上太复杂了。有些计算机科学问题就是这样的——人很容易做,但我们很难或不可能解释我们是怎么做的。机器学习把这些问题从逻辑问题变成了统计问题。你不用写下来自己是怎么识别出X的照片的,而是提供十万个X和十万个不是X的例子,然后用统计引擎生成(“训练”)一个可以在一定程度上区分它们之间不同的模型。然后你给它一张照片,它就会告诉你它是否匹配X或者非X,以及匹配程度。你不用告诉计算机规则,计算机会根据你提供的数据和答案(“这是X,那是非X”)来想出规则。
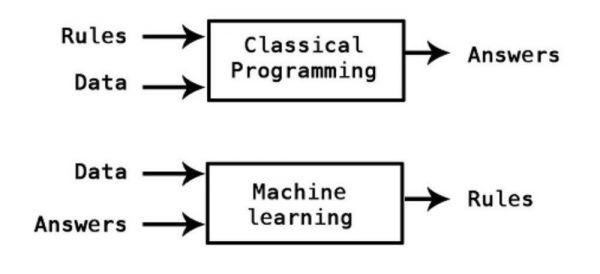
来源:François Chollet,机器学习与一般编程的不同
这种办法对于包括人脸识别在内的一整类问题都非常有效,但会给两个地方引入错误。
首先,你的训练数据(本例中为X和非X)里面究竟有什么?你能确定吗?这些样本集里面的ELSE是什么?
有一个能说明什么地方会出错的例子我很喜欢,那是一个根据皮肤照片识别癌症的项目。一个显而易见的问题是,不同肤色的样本分布比例可以会不合适。但另一个可能出现的问题是,皮肤科医生往往会把标尺放在癌症的照片中(用来测量),所以,如果所有“癌症”样本都都有标尺而所有“非癌症”样本都没有标尺的话,那么相对于那些小色斑,标尺的统计学意义可能反而会突出许多。你在无意中建立了一个标尺的识别器而不是癌症识别器。
如何从解构意义上去理解这个呢?我们需要理解,系统是不理解自己所看到的东西的——它没有皮肤、癌症、颜色或者性别、人的概念,甚至连图像的概念都没有。它对这些东西的了解程度跟洗衣机对衣服的了解程度并无二致。它只是对数据集进行统计比较。那么,再问一下——你的数据集是什么?它是怎么被选出来的?你没注意到东西(哪怕你看着)里面可能会有什么?人群分组会议哪种误导的方式表现出来?你的数据里面会有哪些跟人无关且没有预测价值但又会影响结果的东西?你所有的“健康”照片都是在白炽灯下拍摄的吗?所有“不健康”的照片都是在LED灯下拍摄的吗?你也许无法分辨,但计算机将其视为信号。
第二点更加微妙——“匹配”是什么意思?我们都熟悉的计算机和数据库通常会给出“是/否”的答案。这个车牌是否被盗?这张信用卡有效吗?上面有可用的余额吗?这次航班预订得到确认吗?这个客户号码有多少订单?但机器学习并没有给出是/否的答案。它给出的是“可能”,“可能不是”和“也许”的答案。它给出的是概率。因此,如果你的用户界面把“可能”显示成“是”,这就可能会产生问题。
在最近的几场做秀里面你可以看到这两个问题的体现:训练人脸识别系统识别罪犯的脸部照片(只有罪犯的),然后给一张老实正派的人(通常是政客)的照片,并询问是否匹配,刻意用相当低的置信度的情况下,系统会说YES!——然后这名政客就跟一个银行抢劫犯“匹配”上了。
对于计算机科学家来说,这可能像是蓄意破坏——你故意用歪曲的数据集,故意把精确率设得太低,然后把概率结果(错误地)表示为匹配成功的肯定回答。你可以用小猫的照片而不是罪犯的照片再做一次,甚至用卷心菜的照片都可以——如果你让计算机“在这些卷心菜照片中找到跟这张照片的最接近的匹配”,它会说“好吧,这颗卷心菜跟他是最接近的。”这样搞的系统注定是要失败的——就好像开车撞到墙上然后说“看!它撞了!” 好像你证明出来了什么一样。
当然,你还是证明了点东西——你证明了汽车是可以撞毁的。这类练习是有价值的,因为大家听到“人工智能”时就会想它是智能的——它是“AI”和“数学”,一台计算机和“数学是不会有偏见的”。数学不会有偏见,但数据有。说明这种技术就像数据库一样可能会被搞砸实际上是很有价值的。大家也会用过这种方式建立起人脸识别系统而不理解为什么他们不能产生可靠的结果,然后再把这些产品卖给警方说“这是人工智能——它永远也不会错。”
这些问题对机器学习来说是根本性的,重要的是要强调它们跟与人有关的数据没有任何关系。你可以开发一套系统来识别燃气轮机即将发生的故障,但可能并未意识到自己的样本数据存在偏见,偏向于西门子传感器的遥感数据。同时,机器学习的确非常强大——它的确能识别计算机吃前从未识别的东西,有有着大范围极其有价值的用例。但是,就像我们必须了解数据库非常有用但也有可能会“出错”一样,我们也必须了解它是如何工作的,以免搞砸并确保大家能理解计算机仍有可能出错。机器学习在做某些事情方面要比人好得多,这就像一条狗在寻找毒品方面要比人好很多,但我们不会根据狗的证据来定罪一样。再说了,狗比任何机器学习可都要聪明得多。
译者:boxi
相关推荐
著名分析师 Benedict Evans:人脸识别与AI伦理(一)
著名分析师 Benedict Evans:人脸识别与AI伦理(二)
“史上最危险的发明”?美480位人脸识别专家争议道德伦理
阴谋论下的人脸识别简史
人脸识别十字路口:脸的恐慌
人脸识别技术禁令再来,美国又一城市禁止面部识别软件
危险的人脸识别
人脸识别时代,如何应对“换脸”危机?
人脸识别该不该禁?欧美相继出台AI新规,整治“蛮荒的西部”
“人脸识别”,我们还能承受多少风险?
网址: 著名分析师 Benedict Evans:人脸识别与AI伦理(一) http://www.xishuta.com/newsview10390.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



