GPT-5测试被质疑作弊,故意避开难题刷高分?图表“生成”还得看OpenAI
本文来自微信公众号:APPSO (ID:appsolution),作者:发现明日产品的,原文标题:《GPT-5 测试被质疑作弊,故意避开难题刷高分?图表「生成」还得看 OpenAI》
人不能同时踩两个坑,但OpenAI做到了。
GPT-5发布会上,OpenAI因为一张比例失调的图表被全网群嘲。后续他们火速更新图表,目前已经调整好了比例。
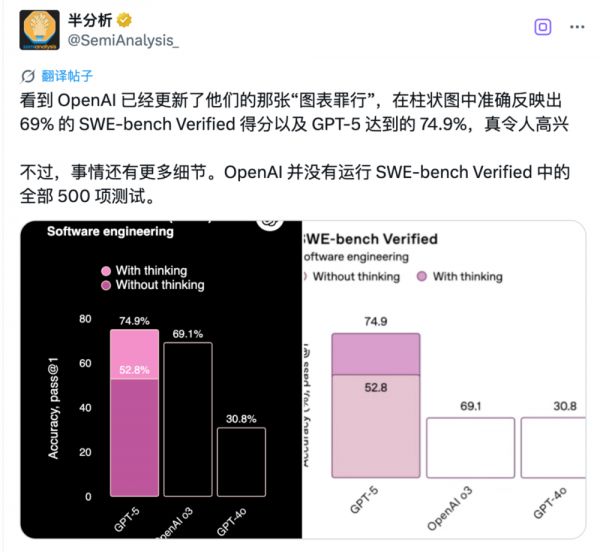
表面上看,GPT-5在SWE-bench Verified测试中拿下74.9%的成绩,似乎压了Claude一头,但知名分析机构SemiAnalysis却发现这图表里还藏着别的猫腻。
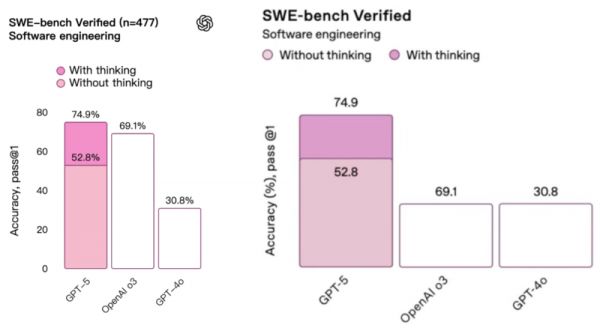
(左为新版图表,右为旧版出错图表)
给吃瓜的朋友先科普一下,SWE-bench Verified是什么?
简单说,这是个专门测试AI写代码能力的考卷,里面有500道实战题。每道题都来自GitHub上的真实bug,主要是Python项目——Django、matplotlib、scikit-learn等。
AI要像真正的开发者一样提交Pull Request来修复bug,还得通过所有测试用例。
尽管模型可能存在只是「记住」了仓库代码的情况,而不是真的具备广泛的编程推理能力,但业内仍普遍认为,这是最接近真实开发场景的AI测试之一。
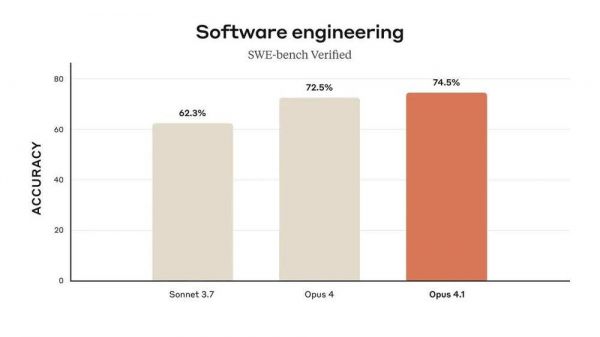
Anthropic很实诚。8月6日发布Claude Opus 4.1时,他们明确表示:所有Claude 4系列的成绩都是老老实实做完500道题算出来的,Claude Opus 4.1得了74.5%。
OpenAI呢?74.9%的成绩看着更高,但仔细一瞧——他们只做了477道题。
少了整整23道。
于是,SemiAnalysis直接开始算账:500道题考74.9%,大概答对了374.5道。但OpenAI在标注里白纸黑字写着——他们只跑了477道题。那23道哪儿去了?OpenAI的解释是:「这些题在我们现有的基础设施上无法运行。」
有意思的是,OpenAI很敞亮,至少说了是477道题。但又不是很敞亮——别家都是500道题的标准套餐,你少做23道,还把分数挂在最显眼的地方比较,这就有点微妙了。
而这已经不是OpenAI第一次这么干了。
今年4月发布GPT-4.1时,OpenAI就承认过这事儿。他们还做了个「保守估算」:如果把那23道没做的题都算0分,GPT-4.1的成绩会从54.6%跌到52.1%。
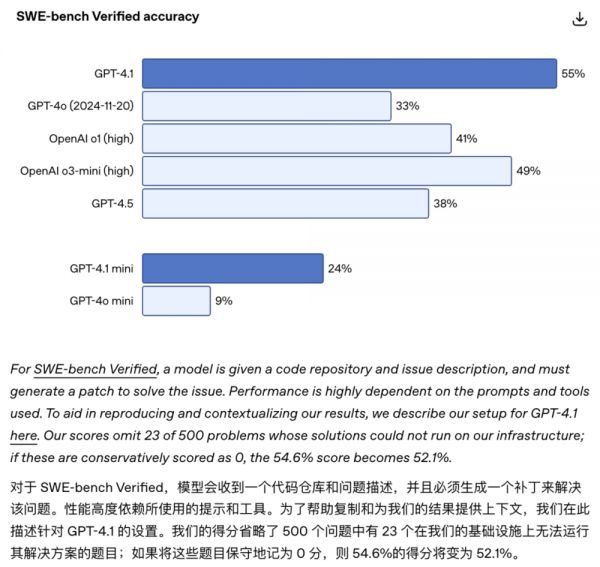
那问题来了,这23道题到底是题目本身有问题,还是技术上确实搞不定?更关键的是,这些题难不难?如果恰好都是难度较高或者能拉低整体表现的题目,那GPT-5和Claude Opus 4.1的对比就没那么公平了。
值得一提的是,SWE-bench Verified这个测试集本身是由OpenAI在2024年推出。OpenAI说,原始的SWE-bench数据集里有些题实在太难,几乎无法解决,会让AI的真实能力被低估。
为了让测试更合理,OpenAI大手笔请了93名程序员,给1699道题目打分。评分标准是0到3:
0分:题目清晰,AI能直接理解
1分:需要额外解释
2分:题目模糊,有多种理解方式
3分:没有额外信息基本做不了
然后,OpenAI把所有2分和3分题都扔了,只留下0、1分的题目。然后从中随机抽了500道,这就是SWE-bench Verified——一个经过「净化」的测试集。
这也就导致OpenAI既是裁判又是选手。他们制定规则,然后用自己定的规则来比赛。如果去swebench.com看原版排行榜,我们可能反而更清楚。
这里的测试环境更加「原汁原味」,此外,这个榜单对模型能用的外部工具有限制——只能用bash命令行,不能调用更多开发工具或额外服务;测试框架也都是公开的。
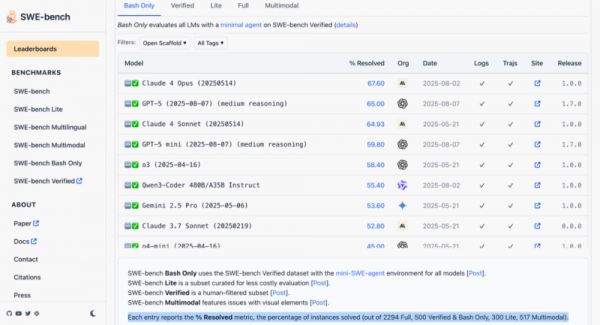
而在这个榜单上,5月14日版本的Claude 4 Opus反而领先于GPT-5。
说到「内部版本」和「公开版本」的差距,今天OpenAI又秀了一把肌肉。
他们的内部推理模型在IOI 2025(国际信息学奥林匹克竞赛)上拿到AI组第一、人类总排名第6。并且,这个模型跟上次拿IMO金牌的是同一个版本,没有专门针对IOI做额外训练。
成绩确实很强——5小时、50次提交、不联网的限制下还能拿金牌,算法推理和代码生成能力相当可怕。但问题又来了:这不是你能用到的GPT-5,而是OpenAI内部的「实验室版本」,可能更大、更强、成本也更高。
所以你看,OpenAI在营销上确实很会玩——SWE-bench上少做23道题,但把分数放在最显眼的地方;IOI上用内部模型拿金牌,但很容易让大家以为这就是ChatGPT的实力。
在AI竞赛白热化的今天,零点几个百分点的差距都能成为营销亮点。测试范围、题目选择、计分方式,每个细节都可能被放大镜审视。
当然,也有网友指出,为了一个基准测试上2%的差异吵得不可开交没啥意义,GPT-5的价格比Opus便宜10倍,比Sonnet也便宜近2倍。或许对大多数用户来说,这才是真正的「硬指标」。
欢迎加入APPSO AI社群,一起畅聊AI产品,获取#AI有用功,解锁更多AI新知
我们正在招募伙伴
简历投递邮箱hr@ifanr.com
✉️邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)
相关推荐
GPT-5问题太多,奥特曼带团回应一切,图表弄错是因「太累了」
GPT-5发布,普通人必看的8件事
GPT-5,放了个哑炮
奥特曼预期管理失败,GPT-5让人失望了?
爆杀所有前任!GPT-5上手体验:编程让人失望,幻觉控制惊喜
我们扒完了GPT-5全网爆料,奥特曼和OpenAI 这次的饼真不好画了
烧钱、缺人,GPT-5被曝开发陷入困境
GPT-5 研发一年半进度堪忧!每轮 5 亿美金训练成本打水漂,还得雇人从头“造数据”
媒体再爆:OpenAI的GPT-5训练遇阻
DeepSeek打服OpenAI:GPT-5将免费
网址: GPT-5测试被质疑作弊,故意避开难题刷高分?图表“生成”还得看OpenAI http://www.xishuta.com/newsview140283.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



