1.5B推理模型新SOTA,RL训练新解法打破「简单题过拟合、难题学不动」的魔咒
(来源:机器之心)

QuestA(问题增强)引入了一种方法,用于提升强化学习中的推理能力。通过在训练过程中注入部分解题提示,QuestA 实现两项重大成果:
Pass@1 的 SOTA 性能:在 1.5B 模型上实现了最先进的结果,甚至在关键基准测试中超越了早期的 32B 模型。
提升 Pass@k:在提高 Pass@1 的同时,QuestA 不会降低 Pass@k 性能 —— 事实上,它通过让模型在多次尝试中进行更有效的推理,从而提升了模型能力。
这一在强化学习训练中的发现,为开发具有更强推理能力的模型打开了大门。QuestA 使 RL 能够高效处理不同难度的任务,消除了通常在简单与困难问题之间存在的权衡。
两难:简单任务导致熵坍缩 vs. 难任务减缓学习效率
多年来,RL 训练一直存在一个需要思考的数据平衡问题:简单任务导致模型过度自信,而难任务提高推理能力,但由于样本效率低下,学习速度变慢。
简单任务倾向于使模型过拟合,使其在特定、更简单的问题上非常准确。然而,这导致模型变得过度自信,从而妨碍了其泛化能力,难以解决更复杂的任务。
难任务提高了模型的推理能力,但具有低样本效率,这意味着它需要更长的时间来学习和进展。稀疏的奖励和任务的难度使得在困难问题上的训练变得缓慢,限制了整体的学习速度。
这个权衡一直是 RL 模型的挑战,近日清华大学、上海期智研究院、Amazon 和斯坦福大学等机构提出的 QuestA 解决了这个问题。通过在训练困难任务时引入部分解决方案提示,QuestA 帮助模型更快地学习,同时不牺牲在简单任务上的表现。这确保了模型能够从简单任务和难任务中获益,提升其推理能力,同时避免过拟合或学习缓慢。

论文标题:QuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation
Arxiv 论文地址:https://www.arxiv.org/abs/2507.13266
HF 模型地址:https://huggingface.co/foreverlasting1202/QuestA-Nemotron-1.5B
GitHub 地址:https://github.com/foreverlasting1202/QuestA
研究者得出的关键结果是:强化学习可以提升模型能力。具体而言,QuestA 取得了以下显著成果:
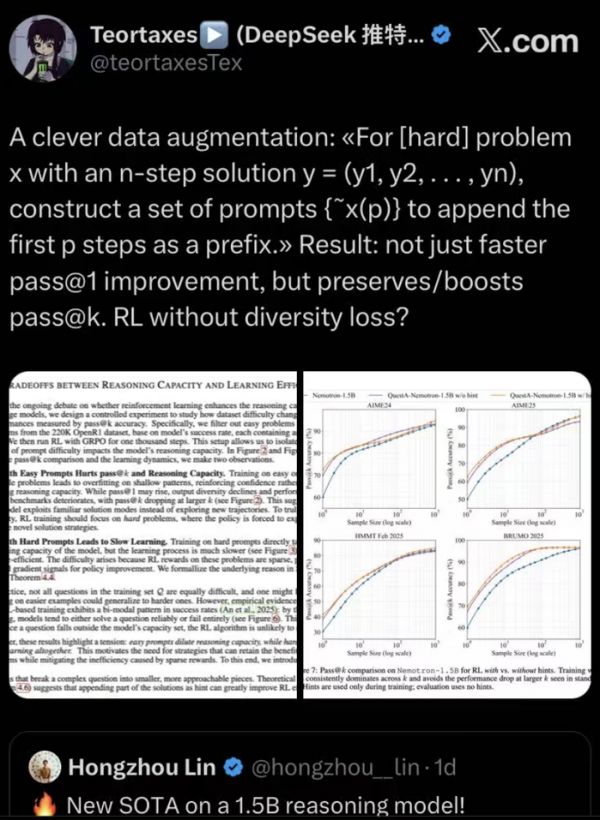
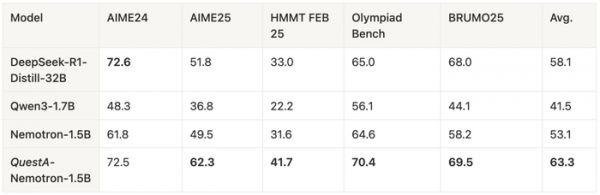
Pass@1 改进:QuestA 显著提高了 Pass@1。研究者在使用 1.5B 参数模型的数学基准测试中达到了新的最先进结果:在 AIME24 上达到 72.50%(+10.73%),在 AIME25 上达到 62.29%(+12.79%),在 HMMT25 上达到 41.67%(+10.11%),甚至超越了 DeepSeek-R1-Distill-32B,尽管它是一个更小的模型。这表明 QuestA 显著提高了模型在平时使用中的表现。
Pass@k 改进:与传统的 RL 方法不同,QuestA 还提高了 Pass@k,展示了模型的容量随着 RL 训练的进行而增加。这是一个关键的区别,因为它表明 QuestA 使得模型能够持续进行探索和推理,而不像其他方法,在优化 Pass@1 时 Pass@k 性能会下降。
X上有人评价称,QuestA 是一种巧妙的数据增强方法,不仅加速了 pass@1 的改进,还保持/增强了pass@k,并且没有多样性损失。这是 1.5B 推理模型的新SOTA。
QuestA 方法:提示即所需
QuestA 通过「数据增强 + 迭代课程学习」的组合设计,实现对 RL 训练的高效改进,核心逻辑如下:
聚焦高难度问题:采用两阶段过滤流程筛选训练数据 —— 首先以 DeepSeek-R1-Distill-1.5B 为筛选模型,从 OpenR1-Math-220K 数据集中选出仅 0-1 次正确(8 次采样)的 26K 高难度样本;再对增强后的提示词进行二次筛选,保留模型仍难以正确解答(0-4 次正确)的样本,最终聚焦不超过 10K 的核心困难任务,确保训练资源用在能力突破点上。
动态调整提示比例:为避免模型依赖提示,QuestA 设计迭代式课程学习 —— 先以 50% 比例的部分解决方案作为提示(p=50%)训练至性能饱和,再将提示比例降至 25%(p=25%)继续训练,逐步引导模型从「依赖提示」过渡到 “自主推理”,实现能力的真实迁移。
轻量化集成 RL:QuestA 无需修改 RL 算法核心或奖励函数,仅通过替换训练数据(用增强提示词替代原始提示词)即可集成至现有 RL pipeline(如 GRPO、DAPO),具备「即插即用」的灵活性。
 QuestA 通过在数据集中每个原始问题前添加部分解决方案提示,对原始问题进行增强处理。
QuestA 通过在数据集中每个原始问题前添加部分解决方案提示,对原始问题进行增强处理。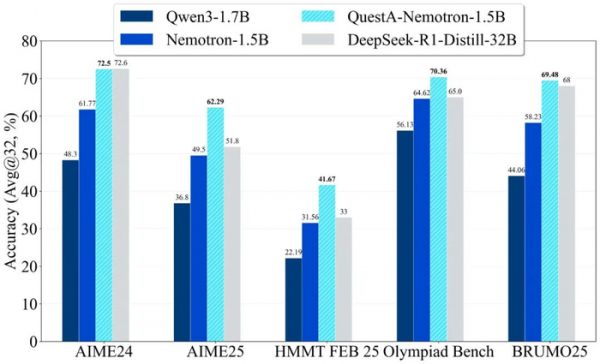
图 1: QuestA 是一种数据增强方法,通过注入部分解决方案,为强化学习(RL)在复杂推理问题上的训练提供有效支撑。研究者基于 OpenR1 中的高难度样本,构建了 2.6 万个高质量增强提示词(augmented prompts),并采用 32K 上下文长度的强化学习对模型进行微调。将该方法应用于 Nemotron-1.5B 模型后,QuestA 带来了显著的性能提升 —— 在所有数学基准测试中,均为 15 亿参数模型创下了新的当前最优(SOTA)结果。
训练细节
研究者使用 AReaLite 框架进行 RL 训练。
具体而言,他们应用了 GRPO 算法,并结合了来自 DAPO 的动态过滤技术,以排除训练中显而易见正确或错误的样本。这一优化帮助聚焦于最难的问题,提升了训练效率。
评估
研究者在竞争级数学基准测试上评估了 Pass@1(32 个样本的平均值)。QuestA-Nemotron-1.5B 在 1.5B 模型中达到了最先进水平,并在多个基准测试中匹配或超过了 DeepSeek-R1-Distill-32B,同时其模型体积小于 20×。
核心差异点:实现真实能力提升,而非熵坍缩
实验结果表明,QuestA 方法在提升模型推理能力的同时,并未损害其多样性。如图 2 所示,即便在问题难度持续增加的情况下,Pass@k 曲线仍呈现出稳定的上升趋势。
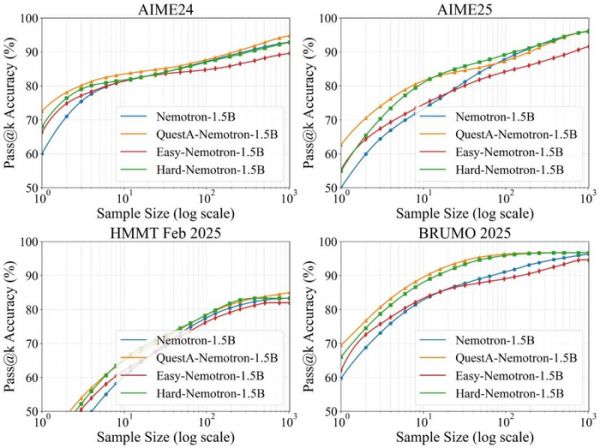
图 2:研究者比较了使用 RLVR 训练的模型在有和没有 QuestA 的情况下的 pass@k 曲线。作为对照实验,我们使用易难不同的提示进行 RL 训练。标准 RL 在易提示下(红色)随着 k 值增大,pass@k 显著下降,而与基准模型(蓝色)相比,表现较差。在难提示下训练(绿色)能够提高 pass@k,但代价是训练时间显著增加。这激发了他们开发 QuestA 的动机,QuestA 通过为困难问题提供框架,提升了训练效率,并且在所有 k 值下提供了更强的结果:RL+QuestA 模型(橙色)在所有 k 值上都优于标准 RL(红色),同时在较大的 k 值下相较于使用困难提示训练的 RL 模型,性能也保持或有所提升。
消融实验
QuestA 同时也在不同的基础模型和不同的数据集进行了实验,都让模型得到了相应幅度的提升,这证明了 QuestA 这个方法的泛用性。具体细节参考 Arxiv 文章。
结论:QuestA 方法彰显强化学习在推理任务中的更大应用潜力
QuestA 方法的研究结果表明,强化学习确实能够助力模型习得新能力。通过同时提升 Pass@1 与 Pass@k 指标的性能表现,该方法证实:强化学习可在不牺牲效率与泛化能力的前提下,持续拓展模型的能力边界。
此外,QuestA 方法有效消除了传统训练中简单任务与复杂任务之间的权衡矛盾,使模型能够在涵盖广泛问题类型的场景下,实现推理能力的极大提升。
这一技术突破对强化学习未来的应用发展具有深远意义。依托 QuestA 方法,我们期待基于强化学习构建的模型如今可处理更多复杂且多样的推理任务,其应用场景已从数学问题求解延伸至逻辑推理及创造性思维等领域。
相关推荐
1.5B推理模型新SOTA,RL训练新解法打破「简单题过拟合、难题学不动」的魔咒
让OpenAI只领先5天,百川发布推理新模型,掀翻医疗垂域开源天花板
数学奥赛冠军都做不对的题,却被拿来考ML模型?GPT-3:我不行
重磅开源!全球首个开源大规模混合架构的推理模型MiniMax-M1发布
36氪新风向丨用 AI 老师替代真人,这是今日头条、好未来们在探索的在线教育的新解法
GPT-5难产内幕曝光,核心团队遭挖空,推理魔咒难破,靠英伟达续命
200美元的ChatGPT Pro正式上线,新模型草莓要来了
“AI登月时刻”,OpenAI模型摘取奥数金牌
谷歌最强大模型终于问世,价格杀到0.7元/百万token
像亚马逊那样打破“大公司魔咒”
网址: 1.5B推理模型新SOTA,RL训练新解法打破「简单题过拟合、难题学不动」的魔咒 http://www.xishuta.com/newsview142708.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



