攻克视频生成难题!合工大、清华、智谱开源「多图像参考生视频」框架Kaleido
(来源:网易科技)

近年来,视频生成技术,尤其是基于扩散模型(Diffusion Model)的技术,发展极为迅速,从文本到视频(Text-to-Video,T2V)、图像到视频(Image-to-Video,I2V)等任务不断取得突破。商业化系统(如 Sora、Veo3、Kling、Vidu)已经能生成媲美专业制作的视频内容,极大提升了创作效率,同时降低了成本。
在此过程中,主体到视频(Subject-to-Video, S2V)生成任务开始备受关注。S2V 的目标是:给定一个或多个参考图像,生成主体外观一致、背景可控的动态视频。这种方法结合了文本生成的创造性和图像生成的精准性,适合数字人、虚拟试穿、电商广告、艺术创作等场景。
然而,现有开源 S2V 模型难以在多主体场景中保持主体一致性,也难以实现背景信息的有效解耦。

论文地址:https://arxiv.org/pdf/2510.18573
代码地址:https://github.com/CriliasMiller/Kaleido
为应对这些挑战,来自合肥工业大学、清华大学和智谱的研究团队提出了开源多主体参考视频生成框架——Kaleido,旨在让开源模型在一致性与背景解耦方面达到最优水平。
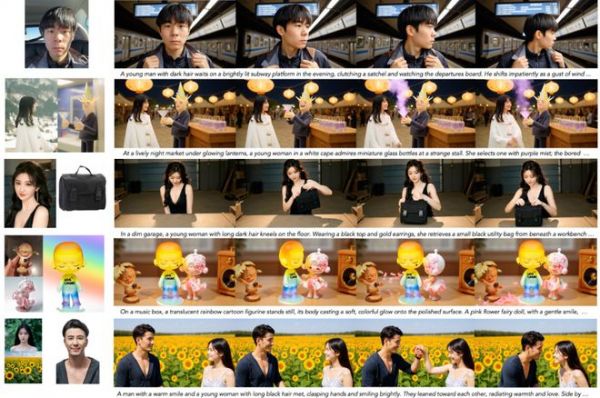
图|Kaleido的S2V生成,涵盖单人和多人场景中的人物、物体及可控背景生成。
实验表明,Kaleido 在一致性、保真度和泛化能力方面均优于先前的方法,代表了 S2V 生成领域的重要进展。
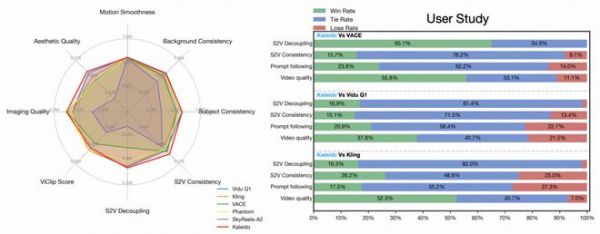
图|S2V 评估(左)和用户研究结果(右)。
研究框架
现有 S2V 方法在保持多主体一致性和处理背景解耦方面仍存在不足,在多图像条件下,这通常会导致较低的参考保真度和语义漂移,可归因于几个因素:
基于此,研究团队提出新的数据构造流水线及对应的条件注入方案,创新点主要体现在三点:
1.高质量多样化数据构建流水线
2.Reference Rotary Positional Encoding (R-RoPE) 条件注入机制
3.两阶段训练策略
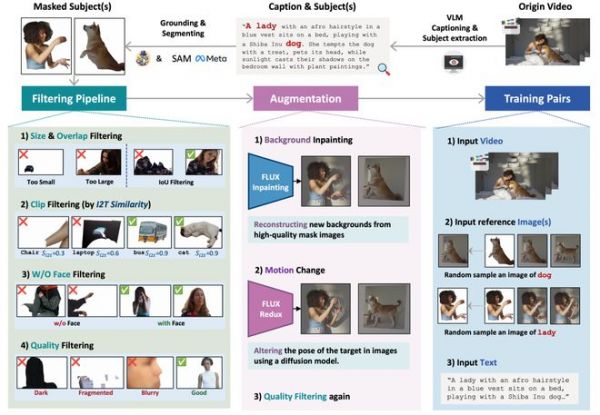
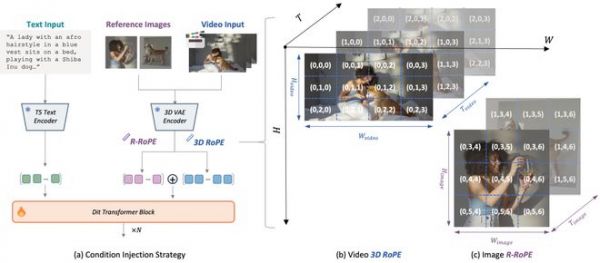
实验结果与效果
在多个维度评测中,Kaleido 展现了强大的性能:
更具体地,消融实验表明:
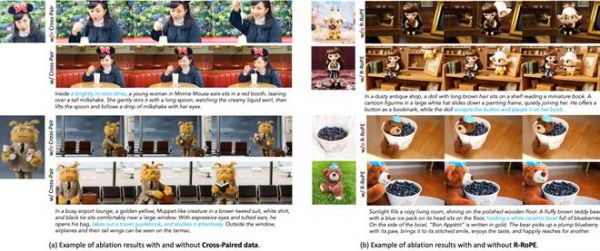
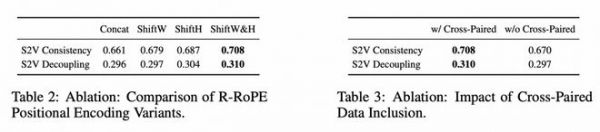
不足与未来方向
虽然 Kaleido 在开源体系中表现突出,但仍存在一些局限性:
未来探索方向包括:
如需转载,请直接在本文章评论区内留言
相关推荐
攻克视频生成难题!合工大、清华、智谱开源「多图像参考生视频」框架Kaleido
对话生数科技CEO骆怡航:参考生视频让创作回归本质,下一步将推进实时生成
智谱AI公布清影新升级:视频生成步入“有声”时代
智谱推出AI生成视频新清影 :支持超高清,自带音效
实测“电商神器” Vidu 参考生图:有素材就能拼出任何图片
大模型低价火拼间,智谱AI“钱途”黯淡
中国AI开源16强,最新出炉
网购下单、朋友圈点赞 智谱展示新AI工具可自动操作手机
AI视频生成有多卷?
阿里再开源,首个MoE视频生成模型登场,电影级美学效果一触即达
网址: 攻克视频生成难题!合工大、清华、智谱开源「多图像参考生视频」框架Kaleido http://www.xishuta.com/newsview143636.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



