潮科技行业入门指南 | 深度学习理论与实战:提高篇(7)——目标检测算法R-CNN
编者按:本文节选自《深度学习理论与实战:提高篇 》一书,原文链接http://fancyerii.github.io/2019/03/14/dl-book/ 。作者李理,环信人工智能研发中心vp,有十多年自然语言处理和人工智能研发经验,主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。
以下为正文。

本文介绍目标检测的常见算法之一:R-CNN。
目标检测
R-CNN
R-CNN是“Region-based Convolutional Neural Networks”的缩写,这里是原论文。它包括三个部分:
生成物体类别无关的Region proposal的模块。这里没有任何神经网络,它使用图像处理的技术产生可能包含物体的候选区域
一个CNN来提取固定大小的特征。这个CNN只是用来提取特征。
每个类别都有一个线性的SVM分类器来判断候选区域是否属于这个类别
它的思路比较简单:首先我们找到可能包含物体的区域,然后用目标识别(Object Recogntion)算法来判断它是否属于猫,是否属于狗,然后选择概率最高的输出。不过和目标识别任务有一点不同在于:目标识别我们假设一张图片一定包含某个目标,比如ImageNet的图片一定是1000个分类中的某一个;但是一个候选的区域里可能不包含1000个分类中的任何物体,因此需要一个”background”类来表示1000个分类之外的物体。
Region Proposal算法的输入是一张图片,输出是多个可能包含物体的区域。为了保证不漏过可能的物体,Region Proposal可能会输出并不包含物体的区域,当然有的区域也可能包含物体的一部分,或者某些区域虽然包含物体,但是它也包含了很多物体之外的内容。这些区域大小是不固定的,可能它们直接可能会重叠。一个“好”的Region Proposal算法应该召回率要高(不漏过),准确率也要高(不输出明显不包含物体的区域),当然最理想的情况是图片中有几个物体,它就输出这些物体的Bounding Box。不过这是不可能也是没必要的,否则它就已经完成了目标检查的任务了!准确判断图片是否包含物体会由物体识别算法(比如CNN)来完成,因此Region Proposal算法的主要目标是在高召回率的前提下保证一定的准确率。另外它的计算速度也不能太慢。
如下图所示,Region Proposal算法可能会输出蓝色的区域,它们可能只包含物体的一部分。我们的物体识别算法输出的概率没有绿色区域的高,而且它们又有重叠,因此我们最终会判定绿色的区域是包含物体的区域。
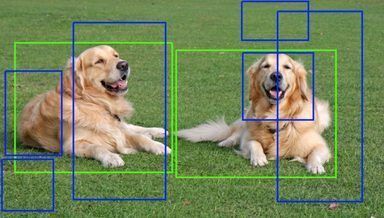
Region Proposal
Region Proposal
最简单的的Region Proposal就是滑动窗口,但是于物体的大小不是固定的,因此我们需要穷举所有可能,这样的计算量会非常大。因此我们需要更好的算法。有很多算法用于Region Proposal,R-CNN使用的是seletive search算法。
selective search算法首先使用基于图的图像分割算法,根据颜色对图像进行分割。如图所示,左边是原图,而右图是分割之后的图。

那我们能不能直接把分割处理的区域作为后续的区域呢?答案是否定的,原因是:
很多物体可能包含多个区域
有遮挡的物体,比如咖啡杯里有咖啡,这个方法是无法分割出来的
当然我们可以通过聚类再生成包含物体的区域,但是这些区域通常会包含目标物体之外的其它物体。我们的目标并不是需要实现物体切分,而是用来生成可能包含物体的候选区域。因此我们会把原来的图片做更细(oversegment)的切分,如下图所示,然后通过聚类的方法来生成更多的候选区域。

Oversegmented图片
由oversegmented图片生成候选区域的算法为:
所有细粒度的分隔都加到候选区域里(当然分割不是矩形区域我们需要把它变成矩形区域)
在候选区域里根据相似度把最相似的区域合并,然后加到候选区域里。
回到1不断的重复这个过程
通过上面的步骤,我们不断得到越来越大的区域,最终整个图片就是一个最大的候选区域。而计算两个区域的相似度会考虑颜色、纹理、大小和形状等特征来计算,这里就不赘述了,有兴趣的读者可以参考论文”Selective Search for Object Recognition”。
下面我们使用opencv来实现selective search。这个算法是在contrib包里,所有需要使用命令pip install opencv-contrib-python来安装。


opencv实现selective search的效果
如果不想安装opencv,那么也可以使用纯Python的开源实现。通过pip install selectivesearch安装后就可以使用。
特征提取
因为论文发表的时间是2014年,使用使用比较简单的alex网络来提取特征,当然我们也可以使用更加复杂的网络来提取特征。论文提取的特征是4096维特征。因为ImageNet训练数据的输入是227x227的GRB图像,而Region Proposal出来的图像什么大小的都有,因此我们需要把它缩放成227x227的。当然原始论文在处理缩放时还有一些细节,包括是否要包含一些context。
检测
每个候选区域都提取成4096维特征之后,我们可以用SVM分类器来判断它是否是猫,是否是狗。因为候选区域可能会有重叠,因此最后会使用non-maximum suppression方法来去掉重复的区域。比如有3个候选区域被判断成猫了,那么有5种可能——三个区域其实都是同一只猫;也可能是三个区域分别是三只不同的猫,当然也可能两个区域是一只猫而另一个区域是另外一只猫。non-maximum suppression其实也很简单,首先找到打分最高的区域,判定它是一只猫,然后再看得分第二高的区域,看它和以判定为猫的区域(最高的区域)的交并比(IoU,暂时可以理解为重叠的比例)是否大于一个阈值(比如0.5),如果大于则认为它是已知的猫而不是一只”新“猫,否则认为它是一个新猫加到猫列表里。接着再用类似的方法判断第三个区域的猫是否”新“猫。注意non-maximum suppression它是对每个类别来说的,如果两个区域很重叠,但是分类器分别判断为猫和狗(猫和狗抱在一起?),那么是不会suppress的。
IoU(Intersection over union)是两个区域的交集的大小比上两个区域的并集的大小,如下图所示。
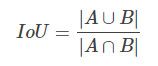
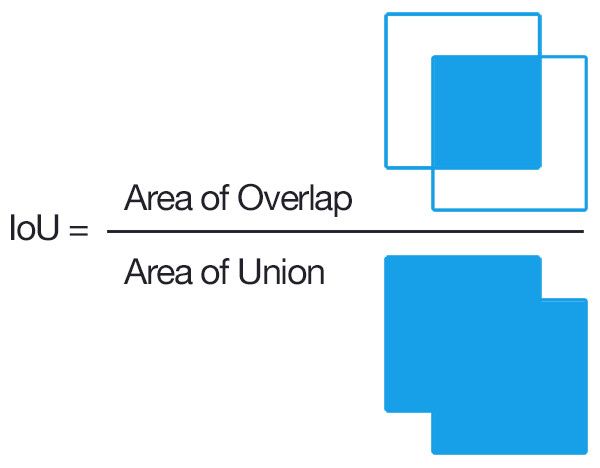
IoU示意图
训练
由于标注了Bounding box的训练数据较少,因此首先使用ILSVRC2012的所有图片进行Pretraining,然后使用标注的数据进行fine-tuning。因为ImageNet的图片是1000类的,而目标检测的类别是不同的,比如VOC数据集只有20类,而ILSVRC2013的检测任务类别是200类。因此我们把最后一个softmax换掉来进行fine-tuning。fine-tuning的数据怎么获得呢?比如对于一张图片,我们可能标注了(100,100,50,40)这个矩形区域是一条狗。我们可以使用Region Proposal算法找出很多候选的区域,如果一个候选区域和标注的区域的IoU大于某个阈值(比如0.5),那么我们就认为这个区域就是狗,否则就不是狗。然后使用这些数据来fine-tuning这个卷积网络。
接下来是给每个类别训练一个二分类的SVM分类器,它的输入就是上面的卷积网络的最后一个全连接层(4096)。这个分类器的训练数据怎么获得呢?和上面的fine-tuning类似,也是看Region Proposal的区域和标注区域的IoU,这个阈值是多少呢?通过交叉验证,发现最优值是0.3。为什么前面fine-tuning时随便的指定一个0.5而这里需要仔细的选择阈值呢?因为前面训练卷积网络不是用于最终的分类,只是用于提取特征,因此大致差不多就行了,而这里训练分类器是用于最终的决策,因此这个阈值对最终的效果影响很大。
Bounding box回归
对于Region Proposal出来的区域,如果被判断为猫,本文还使用了Bounding box技术来”改进“这个区域。因为Region Proposal使用的只是底层的一些颜色纹理等特征,所有它建议的候选区域可能会包括一些多余的像素,而Bounding-box regression会使用CNN的特征来预测,因此能够更加准确的判断物体的边界。使用了Bounding box回归后在VOC2010测试集合上能够提高mAP3.5个百分点。因为这项技术被后面的更新的所取代,所以这里不再介绍,对Bounding box回归细节内容感兴趣的读者可以参考论文的附录部分。
相关推荐
潮科技行业入门指南 | 深度学习理论与实战:提高篇(7)——目标检测算法R-CNN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(8)——目标检测算法Fast R-CNN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(9)——目标检测算法Faster R-CNN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(10)——目标检测算法FPN
潮科技行业入门指南 | 深度学习理论与实战:提高篇(12)Fast/Faster/Mask R-CNN总结
潮科技行业入门指南 | 深度学习理论与实战:提高篇(11)——实例分割
潮科技行业入门指南 | 深度学习理论与实战:提高篇(14)——Mask R-CNN代码简介
潮科技行业入门指南 | 深度学习理论与实战:提高篇(13)——Faster R-CNN代码简介
潮科技行业入门指南 | 深度学习理论与实战:提高篇(6)—— 视觉任务简介
潮科技行业入门指南 | 深度学习理论与实战:提高篇(20)—— 强化学习简介(六)
网址: 潮科技行业入门指南 | 深度学习理论与实战:提高篇(7)——目标检测算法R-CNN http://www.xishuta.com/newsview2101.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



