DeepMind新成果:让AI做了200万道数学题,结果堪忧
编者按:本文来自微信公众号“脑极体”(ID:unity007),作者 藏狐。36氪经授权转载。
在这个春光明媚的周末,一部分成年人却不得不在人间历劫——辅导孩子写作业!其中,又以数学这门学科的杀伤力最为强大。
为了挽救在“抛家弃子”边缘疯狂试探的家长们,不少K12教育平台也开始与时俱进,相继将人工智能加入了数学辅导豪华服务套餐。

在各种新闻中,AI数学老师的画风往往是这样的:
羞辱学渣——只用10分钟作答2017高考数学全国II卷,拿下100分(总分150分), “蒙题”都没这么快;
碾压学霸——在日本的大学入学标准考试、SAT等各国“高考”中拿到了超过平均分的成绩,向状元挺近;
取代人类教师——可以依据人为输入的打分条件,对照答案,在瞬间判断正误。效率比人类判卷老师高出好几个指数级不说,失误率也更低。
想必令不少家长都心动了吧。在这里,我们要扫兴地说出一个真相——即使是目前最先进的人工智能系统,数学水平恐怕连高中生都比不上。
01.DeepMind亲自打脸:AI是个数学渣?
这年头,靠AI判卷打分已经不是什么新鲜事了,给张标准答案小学生都能干。但靠AI教做数学题,就很有技术含量了,考验的则是阅读、推理、计算、逻辑等等综合能力,最起码也得是个“新西方”名师上阵吧。
如果用后者的课时费,请小学生来帮辅导作业,显然大家都会认为是开玩笑。但要是把小学生换成AI,反而令家长们“不明觉厉”喜掏腰包了。
不过,DeepMind的最新研究结果表明,即使是目前最先进的AI系统,做起数学题来连普通高中生都比不过,是不是有点幻灭?

事情是这样的,DeepMind参考英国16岁学龄儿童的数学考试,为AI(深度神经网络)打造了一个包含200万道题目的题库,涵盖了算术、代数、概率、微积分等各种题型,并派出了循环神经网络 (RNN) 和Transformer两位当下性能最先进的模型参与测试。
结果发现,除了四舍五入、加减法、比较大小、数字排序等等简单问题之外,在一些涉及因式分解、混合计算之类的高级题目上,AI的表现都不如人类高中生,连及格线都没达到。
到底咋回事,看看它们是怎么做题的就知道了。
LSTM和Transformer架构都包含一个编码器和解码器。不过在具体运算逻辑上,LSTM会将问题编码为一系列由键和数值代表的具体位置(41+132),然后解码器将下一个字符预测并映射出来(173)。
由于有注意力机制的参与,LSTM能够预先处理一些逻辑上需要先完成的对象,比如知道在计算8 /(1 + 3)时,应该先算出(1 + 3),这已经有点接近人类进行运算时的推理步骤了。
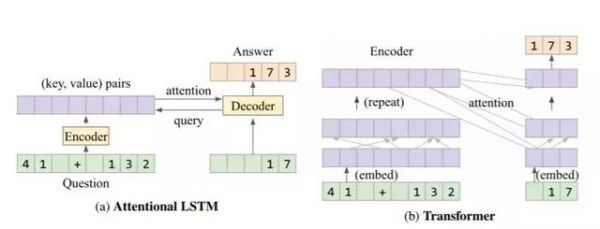
Transformer的不同之处在于,它的编码器能够把数学题转换成一个长度相同的序列, 然后通过注意力机制与位置完全连接的层嵌入任意数学表达式,然后进行转换。
这样做的好处是,Transformer能够使用相同数量的参数进行更多的计算(改变嵌入函数就可以了),同时拥有了连续的“内部记忆”,在处理包含多层级、关联性的混合运算时更有优势,能够在更长的序列上给出正确答案。
计算方式搞清楚了,那么两位模型的最终成绩如何呢?
答案是,非常惨。Transformer模型只答对了14/40个问题,也就相当于E级水平。相比之下LSTM的分数就更惨不忍睹了,放在人类学生身上绝对是要被叫家长的节奏。
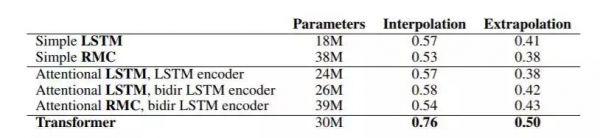
(各个模型处理的参数规模和平均正确率)
02.AI学数学,到底难在哪儿?
一度在计算能力、决策效率上被AI按在地板上摩擦的人类,总算在数学上挽尊了,DeepMind可算也打脸一次AI了。不过,沾沾自喜不是重点,重点是如果要为AI建立一本数学错题集的话,这次实验究竟有哪些值得被记住和补上的短板:
其一是记性太差。
尽管研究人员引入了LTSM和transformer,这是两个在处理机器翻译等序列问题时表现优异的拳头选手,但依然抵不住数学问题的复杂性和语言多样性的压力。在一些需要中间值计算的模块中,比如因式分解、多项式函数等等,系统在进行“思考”时记忆力明显不够用,符号的迁移性和知识的扩展性也因此大受影响,直接影响了结果的准确性。
比如Transformer在计算单纯的加减法或乘除法时,准确率高达90%,一旦加减乘除混合在一起,它就有点搞不清先后顺序了,正确率就下降到只有50%。这表现连计算器都比不上,说明一旦要拼记性、背函数,机器就比不上人类了。

另外,有算力,没知识。
人类在解决数学问题时,应用到的不只有计算能力,还有各种各样的认知技能。比如理解题干,需要将文字或图标转换为算术运算符;确定解题思路,需要进行推理,从已知的公理中找到最佳策略;具体的运算过程中,必须利用工作记忆来完成运算;保持成绩的稳定性,就需要将已学到的知识和规则迁移到同一类型的问题中去……
显然,神经网络还没有办法在“举一反三”的能力上与人类一较高下,它只能处理一些内部存储的问题,无法超越已有的环境去理解新的东西。具体到各个实验项目中, 知识迁移能力越强的模型,在统一数据集上的数学成绩也就越好。

这些短板归根结底,是由数学问题和工程效率的矛盾所导致的。
数学的本质是演绎证明,往往需要架设问题并根据已知抽象出新概念,根据需要提出新的公理体系。这是一个基于推断的极其复杂的“规则游戏”。
而机器的计算模式则是遍历型、经验型的,即通过大规模数据来穷尽所有可能。
用DeepMind研究人员的话来说,数学包含了一个“自洽的宇宙”(self-consistent universe),“简单的AI系统”想要挑战数学命题,显然不太可能。
以“博雷尔-确定性”(Borel-determinacy)为例,虽然只是一个二阶算术命题,但其证明却需要用到无穷阶的算术。想要解决此类问题,就必须把AI系统设计得足够宽泛,以至于能包容绝大部分数学运算。这时的规则量级与复杂性,就不是围棋这种程度可比的了,而可能是在1T个2^中寻找一个最优决策。这时候AI的对手就不是数学,而是资源、金钱与时间了。
03.AI解题:到底应该怀抱怎样的理想期待
说了这么多,用数学水平作为AI的“智商鉴定器”显然有失偏颇,AI也不可能帮助人类解决那些数学领域的未解之谜。既然如此,让AI学数学的意义到底是什么?或许我们必须重新理解二者的关系。
从当前背景来看,提高AI的数学能力大概有两方面的积极作用:
一个是技术层面的,人工智能本质上就是一个将数学、算法和工程实践紧密结合的领域,对数学的探索有利于推动AI技术的全面进步。
举个例子,早在1964年,就有科学家试图让计算机做数学题了,当时提出的STUDENT(Bobrow 1964)系统,就是输入一段规定好描述方式的数学题,然后把自然语言(linguistic form)通过模式匹配映射到对应的函数关系表达。就像把“笼子里有一只鸡和一只兔,问笼子里一共有几只动物”转换成“1+1=?”。这说明,数学要取得好成绩,先得自然语言阅读理解能力过关。
举个例子,就因为没有办法将复杂的题目转换成规范化的数学语言,国立情报学研究所不得不在2016年放弃让人工智能系统Torobo-kun参加东京大学入学考试,2017年中国的“高考机器人” (863计划中的类人智能项目)在对战真人(43名高三文科班学生)时,也以低于人类平均分的成绩落败。
除了文字题干之外,有的题目还会涉及语音识别、图像识别(看图解题)等技术能力。换句话说,想要搞定数学题, 语文课、逻辑课,一科都不能偏!
另一个可能受益的则是社会层面的,针对数学的研究成果,能够有效提升各个人工智能系统在理科解题上的弱势,直接提高知识引擎的性能与效率。
尤其是现在包括综合搜索、XX搜题等在内的各类知识问答平台,已经成为为人们答疑解惑的主要工具。数学解题系统更成了K12教育争先恐后推出的“杀手锏”。但想要提供高品质的数学搜索服务,比如输入数学题,就能精准还原出数学模型、解题步骤以及答案,并不是一件简单的事。
前面我们也说过,数学问题并不仅仅只考验计算能力,还涉及泛化知识库的大量规则,比下围棋的黑白子规则可复杂多了,有时还要面对价值观、意识形态、艺术等很多不可量化的东西。平台们预先内置的数学知识模型在越来越数字化的学习方式面前,搜不到、不匹配、答案“略”,甚至直接用习题册答案凑数的情况,也已经屡见不鲜。
更有甚至,一旦用户输入的问题不符合预定义的模式匹配规则,可能机器就会开始“误人子弟”瞎答了。

如果解题类应用的数学水平始终在及格方面徘徊,连看懂题和正确率都无法保证,还怎么能指望AI系统从学生们的答卷中分析出失分原因并指导其进一步学习呢呢??所谓的靠它降低学习门槛、实现教育普惠和公平,显然也只能停留在幻想层面。
提升AI模型的数学能力,进而增强搜题模型的整体性能,对于众多互联网教育平台和家长考生们来说,意义自然是重大的。

同时,数学本身也是学习(包括机器学习)的起点。
尽管大多数数学问题无法直接被应用,但在寻求验证和推理的过程中,往往会诞生的更强大的推理模型,为更高的机器智能打下坚实的基础。
举个例子,MIT 于2014年在ACL上提出了一种基于统计学习的方法KAZB,根据公式的标注把数学题归类成不同的题型,抽取题目中不同层次的特征,来自动判断题型。
该方法的缺点则是系统没有办法识别出训练集之外的题型。为了解决这个问题, 百度和微软的研究团队分别进行了优化和改进,实现了10%左右的性能提升。
换句话说,提高神经网络的数学能力,虽然不是全部,但却能够为机器推理能力打下坚实的基础。这就像人类小孩学习“鸡兔同笼”一样,不是真的为了方便在成年后数清楚鸡和兔子,而是在这个过程中逐渐学会用一种新的思维模式去理解和认知世界。
或许等到那一天,我们需要担心的就不是机器会做错题,而是人类将无题可做了……
相关推荐
DeepMind新成果:让AI做了200万道数学题,结果堪忧
人类对大脑多巴胺机制理解错了,顶级版AlphaGo背后技术启发脑科学,DeepMind最新成果登上Nature
控制AI之战:揭秘谷歌与DeepMind的爱恨情仇
乂学教育松鼠AI创始人栗浩洋:知识地图是实现“哪里不会学哪里”的关键| AIAED全球AI智适应教育峰会
突发,一年烧掉40亿元后,DeepMind联合创始人“被休假”
DeepMind和暴雪发出神秘预告,终极人机大战要来了?
谷歌与DeepMind的矛盾:或爆发于利益,终结于权属
谷歌AI大转向:鲸吞DeepMind健康部门,在印度成立首个AI实验室
DeepMind官博详解AI打星际争霸:靠战略水平 而非手速
DeepMind联合创始人加入谷歌,负责AI政策方面工作
网址: DeepMind新成果:让AI做了200万道数学题,结果堪忧 http://www.xishuta.com/newsview3320.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



