当监考系统中的人工智能,也变成人工智障
本文来自微信公众号:世界说(ID:globusnews),作者:李子,责编:张希蓓,头图来自:《人工智能》,原标题为《当人工智能变成人工智障》
从去年开始,因为疫情的原因,许多美国大学的大课都转成了网课。Zoom、Canvas和Microsoft Team成为了课程交流的主要平台,同学们开始逐渐熟悉线上交作业、线上讨论等等,甚至还组织了线上social。然而,比起上课时的断网、无聊和注意力涣散,线上考试成为了许多人的梦魇——特别是少数族裔。
纽约大学法学院的中东裔学生Alivardi Khan怎么都登不上考试界面。考试软件的面部识别功能,一直提示他“没有足够的光”,尽管他在的房间光线十分充足。“这根本就不是光的问题,面部识别算法有种族偏见。”他在推特上抱怨道。
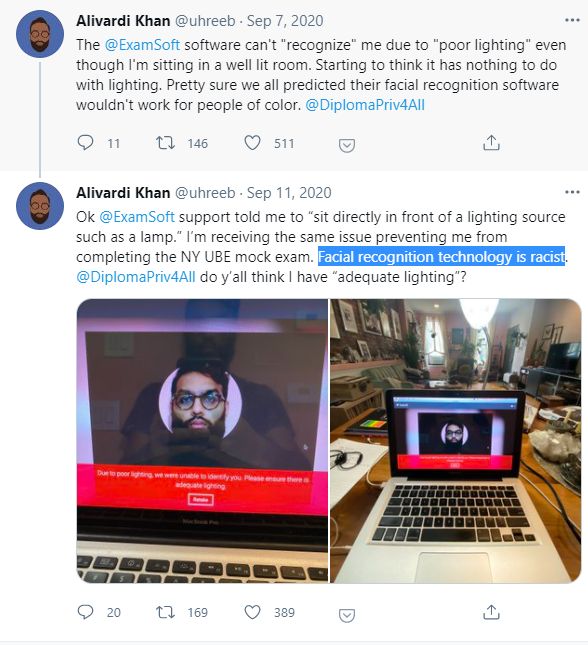
● Alivardi Khan在推特上讲述了自己的窘况 / 网页截图
而另外有好几所大学,使用的是一款叫Proctorio的在线智能监考工具。通过摄像头和人工智能(AI),Proctorio能够自动识别学生的面部。闭卷考试的时候,学生必须全程盯着屏幕,如果有移动、离场的情况,会自动触发软件的“警报”,而监考人员则会收到通知。
此外,这个软件还会实时监控眼睛移动、打字规律,从中找出作弊的蛛丝马迹。这个软件遭到了大量学生的抵制,少数族裔尤甚——软件无法识别面部,无法进入考试界面;好不容易登录进去,软件在中途却频频发出警报、暂停,甚至将人从考试界面踢出去。
一个非裔女生的妈妈Janice,把女儿挣扎着考试的情况发上了推特。“电脑调亮,不管用;窗子打开,过曝了;台灯打开,又太黑。她最后必须在头上打光,才能让软件正常工作。”尽管如此,试了9次,只有两次成功。
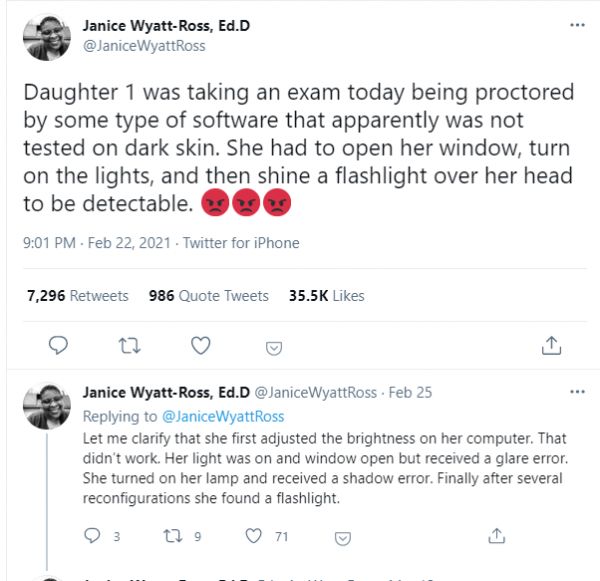
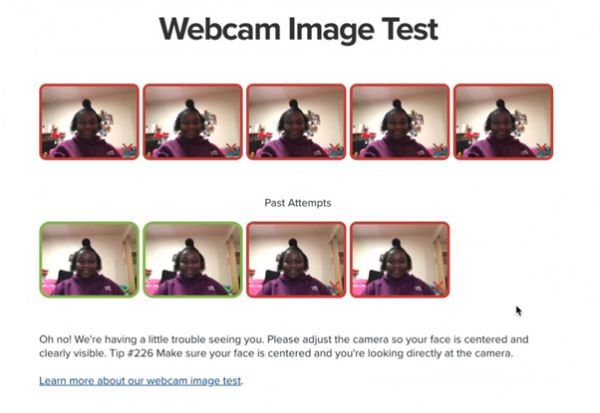
● Janice在推特上公布的女儿使用在线考试软件的截图 / 网页截图
许多学生都在抱怨这个软件极其不人性化、十分难用。有的必须给教授发信请求另外的安排,有的被迫在考试时间求助于软件技术支持,有的在学校论坛或者推特上交流沟通“技巧”,例如什么样的角度、什么样的光线能够让识别更方便。有的同学试图反映到学校,甚至发起倡议,禁用这些为他们带来极大不便的监考软件。在原本就压力巨大、孤立无援的网课情景下,这些烦心事每每让人加倍崩溃。
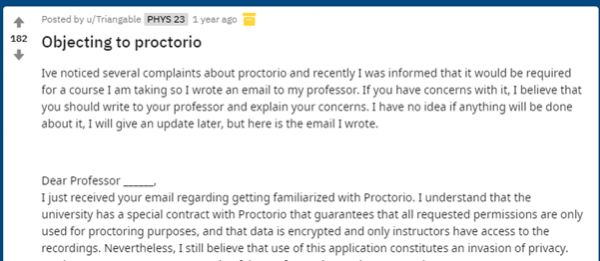
● 有人在Reddit上发出了倡议 / 网页截图
开源“血统”的监考软件,置信度堪忧
迈阿密大学计算机系新生Akash Satheesan是印度裔,过去一年他也深受在线监考软件困扰。他决定“反向工程”这些监考软件,找出其代码和算法的问题。他把Proctorio的Chrome扩展应用的代码抽出来仔细查看之后发现,一些面部识别的功能代码指向的文件,与另一个开源的图像软件库OpenCV的文件名高度相似。
Akash把Proctorio扩展应用中的算法复制出来,用FairFace数据库中的1万1千个面部数据对其进行了一系列测试。接着,他再用来自OpenCV的面部识别模型测试了同样的图像,两者的结果几乎相同。这印证了他的猜想——监考软件 Proctorio 的确是直接挪用了OpenCV的产品。尽管Proctorio声称自己的技术是独立开发的,但在其软件的授权页面,的确找到了OpenCV的相关证书。
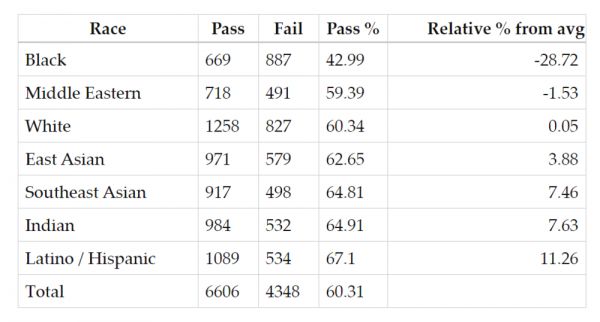
● Akash Satheesan在自己博客上公布的Proctorio对不同族裔面孔的识别率 / 网页截图
测试的结果也让人汗颜。在Akash进行的测试中,算法在57%的情况下,无法准确识别非裔面孔,41%的情况下无法识别中东裔面孔。对其它面孔的识别率也并不高——失败率在30%~40%不等。的确,在抱怨软件难用的同学中,亦不仅仅是少数族裔。而此前就有CS领域的研究人员指出,OpenCV的训练算法,对不同种族面孔识别的成功率有较大的偏差,特别是对少数族裔的识别和匹配,置信度十分一般。
是什么导致了识别的偏见?
不管如何,有一个问题始终有如房间大象:软件对有色人种的面部识别存在偏见,这是“种族歧视”吗?推特上,两派为此争执不休。一方表示,“软件本身无错,只是设计得不好”,而另一方则认为“偏见=种族歧视”。但实际上,软件和算法的设计、应用是一整个链条,从原理到实践,每一环都有出问题的可能。
从原理上看,图像的面部识别的核心在于用大量已有的数据,在进行一系列标准化处理之后(例如调整角度、去除背景等等),投入神经网络,提取出面部特征,然后再将面部特征与已有的数据库做比对。以非常有名的开源面部识别工具OpenFace为例,它也用了之前提到的OpenCV的软件库里的工具对图片进行预处理。简单来讲,它是用50多万张人脸数据训练出来的一个模型,可以从图片中提取出来面部的128个特征点,再把这些特征点进行比对。
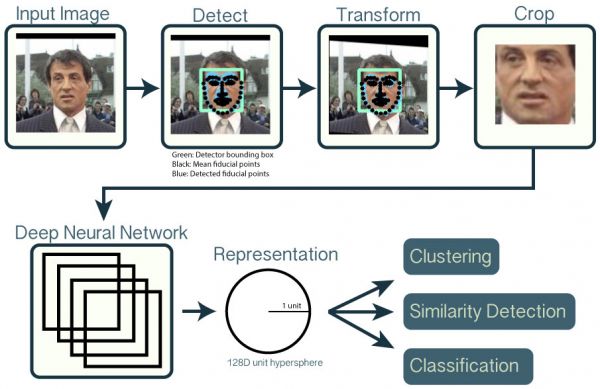
● OpenFace工作原理 / Github
比起大公司的商用模型(例如Google的FaceNet或者Facebook的Deepface等等),OpenCV和OpenFace不仅开源,还可以在Torch、Python环境中运行,只需要普通电脑的GPU即可。使用的神经网络模块也通过训练调校过,更是有一系列的机制对数据进行压缩、低维化处理,实现实时的处理,尤其可以在手机等便携设备上使用。
但这种“方便”的工具,在数据训练和模型准确度上,都有不小的问题。而图像识别的偏见,很大程度上是训练不足带来的——也就是说,原有的50万原始训练数据中,除了白人之外少数族裔的面孔严重缺乏。即使它对图片进行了亮度调节和灰度处理,不同族裔之间的面部特征也有相当大的区别,这让算法对于非白人的面部特征提取能力不足,从而在识别上出现偏差。已经有研究表明,用亚洲人图像占比更大的数据库训练出来的模型,在识别亚洲脸上,比一般模型更好。
这其实跟人对“异族”的识别有异曲同工之处。有不少神经科学研究都指出,人们对于“不常见”的陌生族裔的面部,识别能力不足。有一个段子就是“欧美人看亚洲人长得都一样”,拿着朋友的证件蒙混过关。这对人工智能、机器学习而言也是一样的道理——它们“不认识”其它族裔的人。
在训练数据有限的情况下,若想要追求准确度,反而有可能会将数据中的偏差放大,对“少数”更加不利。比如,一个数据库里有98%的男人,只有2%的女人。经过训练的AI即使可以识别所有男人、完全不管那2%的女人,那也能有98%的准确度。但是那2%的女人,对机器就等同于不存在了。一些研究者认为,现在的图像识别开发者,往往会陷入盲目追求“准确度”的陷阱里去;训练出来的模型,在某一个数据库上的精确度可以达到非常高,这在技术领域被称为“过拟合”,但搬到现实中,就难免会出现严重偏差。
偏见发展到哪一步,会积累成歧视?
软件开发者们知道这个问题吗?可能知道,但面部识别技术可能存在的偏见,并不是许多做监考软件的小公司优先考虑的事情。OpenCV是一款训练成熟的开源软件,有广泛应用的基础,但却并没有人在各种应用环境下为其重训、纠偏。在当下,人工智能逐渐变成一个拼硬件和数据库实力的战场,然而大部分小公司实力有限。现有的数据库、模型和算法,恐怕无法支撑从实验室到多元、复杂的真实世界的过渡,这一过程中必然会出现大量问题。
纠偏也是一个非常困难的事情,即使对于大公司来讲也不容易。谷歌曾经出现过用黑人图片反搜、结果出现“猩猩”这种情况。他们的做法,是直接把猩猩这个标签给隐藏了,并没有从根本上解决图片识别里潜藏的错误偏见。
在机器学习研究的领域里,数据库还是相对比较“干净”,标签、分类等等都相对规范。然而在商业领域采集到的数据,很多都非常潦草,训练出来的算法也有很大问题。“垃圾进,垃圾出”(Garbage in,Garbage out),是业界对于糟烂数据库训练出糟烂智能的吐槽——很多时候,甚至是自嘲。
英国巴斯大学计算机系教授Joanna Bryson说,“偏见,只是机器从数据中拾取的规律(regularity)而已。”在人工智能和机器学习的范畴里,“偏见”并不是一个带有价值判断的词汇。然而,在涉及到现实应用的领域,情况就不一样了。现在的机器,当然不具备体会情感或者故意施加偏见的能力,只是诚实地反映了数据库乃至社会中真实存在的偏见,而这些反映有时候并不是我们想要的。
更大的问题,是把技术语言不加审视地“翻译”成为客观现实,甚至替代人类的判断。这种技术层面的偏差(bias)便会在社会上迅速地积累成实际的歧视(discrimination)。
在实验室的环境中,一般来讲,一个模型对于数据匹配的判定,是以“置信度”为标准的。从原理上讲,它们并不是“不认得”非裔面孔,只是“置信度”不够高——也就是原始数据训练不足的情况下,在判定上没有那么大的把握。
然而,Proctorio等监考软件的问题就在于,一旦低于某个置信度的阈值,它的结果就直接是“不认得”(或者判定失败),这直接给大量少数族裔的使用者带来了严重的不便。考试是一个讲求公平公正的场合,这种使用上的不便、特别是对特定人群的不便,严重影响了考试的公平。从这个角度上讲,不加考虑地使用带有偏见的工具,的确是种族歧视。
另外一个严重的问题,是特定人群和某些特征的数据上的“关联”,直接被运用在对风险的“判定”上。哈佛大学计算机系教授Latanya Sweeney发现,在搜索引擎上搜典型的黑人名字,搜索引擎会有超过80%的概率在搜索建议里提供“逮捕”“犯罪”等词汇,而没有种族特征的却只有不到30%。
2019年美国国家标准和技术研究所的一份研究报告,分析了市面上200多个面部识别算法,发现大部分对少数族裔的识别都存在或多或少的偏见,而在所谓的“一对多”的算法里(例如警方采集一个人的面部特征并比对犯罪数据库进行比对),非裔女性的假阳性概率最高。也就是说,非裔女性最容易被系统误判成有前科的犯罪分子。
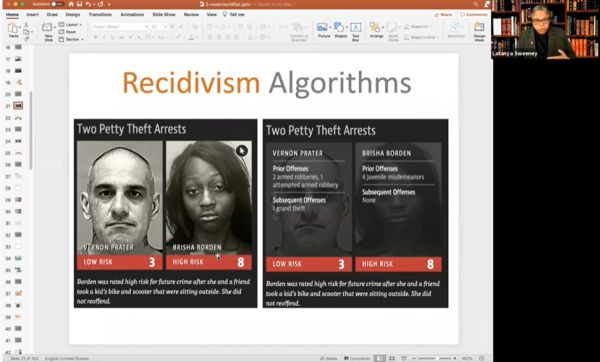
● Latanya Sweeney在课堂上讲述了自己的发现:带有种族偏见的算法 / 视频截图
说到底,在这个阶段,将人工智能作为一切的“守门人”和“判定人”,时机还相当不成熟。机器学习将复杂的现实压缩成信号,再用一层层的神经网络去把这些信号“模拟”成现实的样子,形成一套标准化的认知(比如一个人的脸“该长什么样”)。然而我们所处的世界,还有无数多特殊的、多维度的、多角度的“现实”。面部识别工具给我们提供的方便、快速、“智能”的场景,是不可能概括这种复杂现实的。
在强大的面部识别技术下,我们怎么办?
在当下,人工智能提供了一个非常方便而强大的“解法”。特别是面部识别技术,能够在暗处、无阻碍地对人进行监视以及数据的收集,这无疑给安全和监控系统提供了大量方便,甚至某种“路径依赖”。毕竟,买一套成熟的解决方案,比自己研究开发容易多了。
但是,对这些“解决方案”不加审视地广泛应用,对于少数族裔、少数族群、特殊情况的无视,对“标准化”“理想化”以外情景的缺乏考虑,无疑会极大地影响软件应用上的公平公正,乃至方便普适。
所以,人工智能的“歧视”,说到底还是人类现有偏见的积累。我们还在不断地完善我们自己的认识,在不断的发展和学习中纠正我们自己的偏见,去消除歧视和不公。因此,我们也需要给机器以机会完善自身,成为我们的认识伙伴,而不是用智能、“客观”的“模型”,来武断地代替我们去认识世界。
对于我们每个人来说,需要警惕身边的数据“采集”,多注意一下这些技术的用途,拒绝没有同意(consent)的技术应用。只有这样,才能促使技术开发和运用向更人性、更保障隐私、更公平的方向发展。
本文来自微信公众号:世界说(ID:globusnews),作者:小世儿,责编:张希蓓
相关推荐
当监考系统中的人工智能,也变成人工智障
人工智能还是人工智障?带你看看大型算法翻车现场
高考前最后一天,AI 监考老师已就位
人工智能理解常识的数十年挑战,如何让 AI 不再“智障”?
你和人工智能的对话,正在被人工收听
人类唯一的出路: 变成人工智能(五)
网课带火“云考试” 监考服务会成为新商机吗?
人类唯一的出路: 变成人工智能 大融合(四)
当AI变成人类
人工智能,还是“人工”去实现智能?从ScaleFactor的倒掉谈起
网址: 当监考系统中的人工智能,也变成人工智障 http://www.xishuta.com/newsview42821.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



