学习复杂技能的大招:ACT-R 理论
神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:技多不压身,谁都想多学习几门技能。但是,要想学会一门复杂技能可没那么容易。这里面有什么窍门吗?我们执行技能的时候大脑是怎么指挥我们的呢?学会一样东西对我们学习另一样东西能起到多大的帮助?也许综合运用大量心理学成果的 ACT-R 理论能够帮助我们。文章来自编译。

划重点:
所有的科学理论都建立在范式之上
人的记忆系统分为陈述性与程序性两种
ACT-R 理论的范式是问题解决
问题解决的三步走:
用陈述性系统形成“问题表示”
产生式就当前表示相互竞争
产生式的执行会改变你当前的状态
我们是怎么学习像编程、物理或驾驶飞机这样的复杂技能的呢?我们大脑发生哪些变化可让我们执行这些技能?学习一样东西对我们学习另一样东西能起到多大的帮助呢?
这些都是难题。大多数实验只是想解决这些问题之中的一小部分。学习的时间表是怎么影响记忆的?重读好还是检索好?你应该练习一整项技能,还是一点点练习再拼凑起来?这些并不能直接解答以上那些大的问题。
这就是约翰·安德森(John Anderson)的 ACT-R 理论如此雄心勃勃的原因。[1] 它试图综合运用大量心理学方面的工作,从而形成一幅我们如何学习复杂技能的大图景。就算理论证明不是全部,但也有助于阐明我们对这一问题的理解。
首先,我们要对科学范式做一点说明
在开始解释 ACT-R 之前,我需要退后一步,谈谈该如何思考科学理论。
所有的科学理论都是建立在范式之上的。范式就是例子,是你用来描述现象的核心。牛顿的范式是掉下来的苹果以及绕轨道运行的行星。达尔文的是雀类的喙。显然,牛顿的理论并没有局限在掉落的水果上,达尔文也没有只针对偏居小岛一隅的鸟类。不过,这些都是他们的示例,用来为更广泛的理论奠定基础。

现如今,我们认为力学和进化理所当然应该是科学,因此它们的原始范式案例在很大程度上已变成历史脚注。[2]我们可以忽略它们的起源,而只专注于理论的应用。
但心智理论不是这样的。没人相信我们已经找到了大一统理论,可以完全解释大脑是如何工作的。不过,我们也不是一无所知,我们知道的比这多多了。科学家收集了大量证据,这些证据严格约束着任何有效的心智理论。但是我们的大脑很复杂,适用的可能理论仍然有很多。
考虑到这一点,那么ACT-R 会拿什么作为其认知技能的范例呢? ACT-R 侧重于问题解决,尤其是在代数或编程等定义明确领域的问题。说得具体一点,它的重点是智力技能。 ACT-R 没有告诉我们该如何移动身体,也不负责解释我们是怎么将来自眼睛和耳朵的输入加以转换,然后去理解问题的。
这一范式的代表性似乎不是很强。的确,大多数的人类经验跟用 LISP 编程都不像。不过,一个好的范式不需要是它要建模的现象的原型。事实上,情况往往正好相反,最好的范式往往不同寻常,因为它们少了更典型情况的那种混乱。牛顿力学必须克服这样一个事实,即我们其实身处在一个摩擦无处不在的环境里,大多数物体最终都会静止。达尔文需要加拉帕戈斯群岛那样的特殊环境,这样雀类才能够在相对孤立的情况下适应独特的生态位。
在这个范式里,ACT-R 做出了一些令人印象深刻的预测,并设法解释了大量的心理数据。因此我认为,如果我们想要更好地了解我们是如何学习事物的话,就应该好好理解这一理论。
ACT-R 理论基础:陈述性记忆系统与程序性记忆系统
ACT-R 认为我们有两种不同的记忆系统:一种是陈述性的,另一种是程序性的。
陈述性系统包括了你对事件、事实、想法和经历的所有记忆。你有意识地体验的一切都是这个系统的一部分。它既包含了你的直接感官体验,也包含了你对抽象概念的知识。
程序性系统包含了你能做的一切。它既包括了运动技能,比方说系鞋带或在键盘上打字,也包括心理技能,比方说加减乘除或写电子邮件。
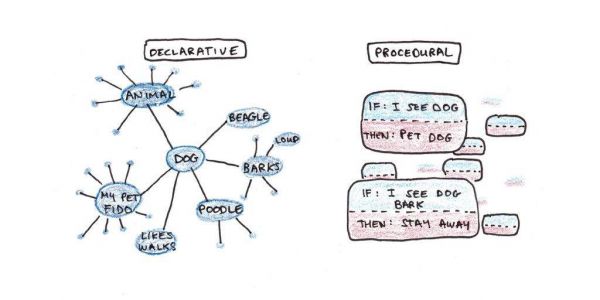
ACT-R 对复杂技能的解释是这两个系统之间的持续交互。陈述性系统对外部世界、你的内心想法和意图等做出反应和表示。程序性系统会根据这些表示,采取外部行动或做出内部调整,从而让你离目标更接近。
为什么要设立两个独立的系统?糅合成一个系统不是更简单吗?但是有一系列令人印象深刻的证据表明,这些系统在大脑里面是不一样的:
失忆者可以通过程序性系统去学习,但不能通过陈述性系统学习。他们可以学习执行新任务,但之后,他们并没有自己被教过的记忆。
诱导实验仅适用于陈述性系统,但不适用于程序性系统。比方说,呈现“计算机”这个词可以加快人们访问计算机相关记忆的速度。尽管如此,但这并不能加快他们掌握使用计算机的速度。
程序性记忆是单向的。这就是为什么顺着念字母表要比倒着念容易得多。倒着念的时候,你需要生成要背诵的字母序列,在脑海里面排练好,让陈述性表示处于活动状态,最后再操纵它们来颠倒顺序。
陈述性系统有Fan效应(编者按:大概意思是与某一概念有关的事件学习的越多,提取其中任一事件所花的时间越长)。在陈述性记忆里面,节点之间的链接是双向的,任何一个节点都可以访问另一个节点。但是,有很多外向链接的节点与链接的任何节点的关系都不是太强。比方说,一张小猎犬的照片很容易让人想起“狗”,但看到“狗”这个词你未必就会想起某一张小猎犬的照片。
神经科学研究表明,这两个系统在大脑的位置是不一样的。海马体和联想皮质对陈述性记忆起到了关键作用。相比之下,程序性系统似乎依赖于皮层下结构,比方说基底神经节与多巴胺网络。
陈述性系统
陈述性记忆的基本单位是块(chunk)。这是一个绑定了大约三条信息的结构。确切的内容会因块而异,但假设它们是简单的。 “十七是一个数字”就描述了包含有三个元素的块:[17][是][数字]。
既然块如此的初级,我们又是怎么理解那些复杂事物的呢?一种解释是,通过经验,我们将这些块连接成了复杂的网络。然后,我们可以遍历这些网络以获取我们需要的信息。
陈述性记忆结构非常庞大,但任何时候只有少数块处于活动状态。这反映了意识觉知(conscious awareness)与记忆之间的区别。当我们需要记住某些东西时,我们会通过网络进行搜索。对于练习过的记忆来说,这相对容易,因为大多数相关想法只有一两步之遥。而对于新想法来说,这要困难得多,因为它们与我们的其他知识的整合程度较低,因此搜索过程要更加费力。
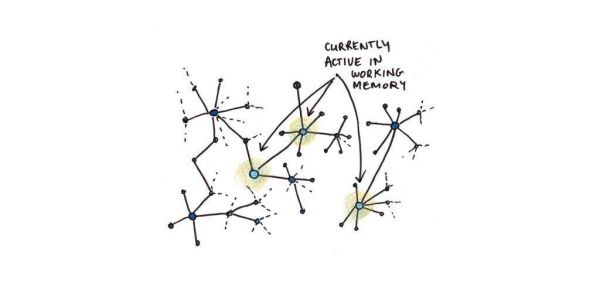
节点怎么才会被激活?有三个来源:
首先,你感知来自外部世界的事物,这些事物会自动激活记忆里面的节点。 (也许是你看到了一条狗,然后一些与狗相关的节点就被激活了。)
其次,你可以在心里默诵事物,好将它们保存在记忆里。想想看,你打算记住某人的电话号码并写下来的过程。你可以自己重复一遍,以“刷新”不再存在的听觉体验。
第三,节点可以激活相连接的其他节点。当一个想法导致另一个想法时,就会发生这种情况。ACT-R 还没有完全搞清楚这种传播激活机制的确切细节。但安德森假设活跃的块往往与它们在这种情况下可能的有用程度有关。
陈述性系统有一个隐藏的庞大的长时记忆网络,以及与我们的意识觉知相对应的短暂活跃节点,这一点令人印象深刻。为了解决问题,我们利用这个系统来决定下一步该做什么。但是,根据 ACT-R 理论,这个系统存在惰性。必须有其他东西将其转化为行动。这个东西就是程序性记忆系统。
程序性系统
程序性系统的基本单元是产生式。系统有一个 IF -> THEN 的模式。举例来说,一个产生式也许是“如果我的目标是求解 x,而且方程 ax = b 成立的话,则可将方程重写为 x = b/a。”
可以将产生式想象成解决问题所涉及的原子思考步骤。每当你需要采取行动或做出决定时,ACT-R 就会把它建模成为激活产生式。
与庞大、相互关联的陈述性记忆不同,产生式是模块化的。每一个产生式都是一个个孤立的单元,独立地习得和强化。相对于解决简单问题,解决复杂问题要牵涉到更多的产生式,但基本成分是一样的。
对于陈述性记忆中的每一个活跃表示,会有很多不同的产生式相互竞争,目的是找到当前情况的最佳匹配。当一个产生式与陈述性记忆中的某个活跃表示匹配,并且执行这个产生式的预期价值超过采取不同行动或等待的预期成本时,它就会触发。然后你采取行动,世界的状态(或你的内在心理状态)发生了变化,接着不断重复这个过程。

如果你多次重复了一系列的动作,就可以将这系列动作合并为一个产生式。因此,只需激活一个产生式就执行从开始到结束的整个一系列心理步骤。虽然这么做是更快了,但灵活度也下降了。慢慢地,这可能会导致技能难以转移到应付新情况,因为针对特定问题你已经把特定解决方案给自动化了,而不是每次都从头开始走一遍一般程序。
ACT-R 是怎么声称你解决了问题的
我们总结一下这里介绍的整个推理过程:
你在陈述性系统里面形成了问题的表示。这种表示是你当前的感官体验与长期记忆和短期复述缓存的结合。
产生式基于当前的表示进行相互竞争。谁获胜要取决于与陈述性记忆的活动块的匹配程度以及你期望从采取该行动中获得什么好处。
每个产生式的执行都会改变你当前的状态。你要么在外部世界采取行动,而行动又会通过感官渠道改变你的陈述性表示,要么产生式会改变你的内心状态。
这一过程会不断重复,直到问题得到解决。
我们是怎么获得技能的?
按照 ACT-R 理论,学习技能被认为是一个获得和强化产生式的过程。
一开始的时候,产生式是通过类比来学习的。我们会在我们的长时陈述性记忆里面搜索类似的问题。然后我们尝试将其与我们当前对问题的表示进行匹配。一旦找到匹配,我们会建立一个产生式。
ACT-R 认为,我们不是按照明确的指导,而是通过示例来学习的。当我们看起来好像是按照指导学习时,我们其实是先根据指导生成了一个示例,然后再用这个示例建立一个新的产生式。
产生式一旦建立起来之后,就会通过使用得到加强。每当你用了一个产生式来解决问题时,在类似情况下再次选择它的可能性就更大。强化过程非常缓慢。这就是为什么需要大量练习才能擅长复杂技能的原因。让所有产生式都能够流畅地执行需要大量的重复和微调。
根据 ACT-R,对于解决问题来说唯一重要的是找到解决方案,而不是如何找到。过程中的错误会浪费时间,对学习没有帮助。因此,安德森提倡睿智的导师要在解决问题的过程中立即纠正错误。
学习迁移
对于有相当多的数据支持的学习和迁移,ACT-R做出了有力的预测。
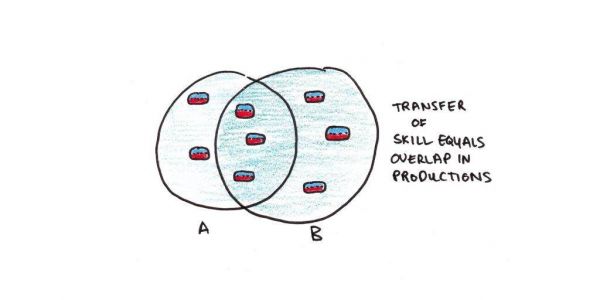
其中一个关键预测是,预测两种不同技能之间迁移的规模要取决于二者共享的产生式的数量。这个预测的效果如何呢?
下图来自安德森的《心智法则》(Rules of the Mind)。预测是迁移应该与产生式的数量成线性关系。我们所看到的正是如此。[3] 在我看来,这是 ACT-R 或类似的东西可以解释认知技能迁移的最佳证据。
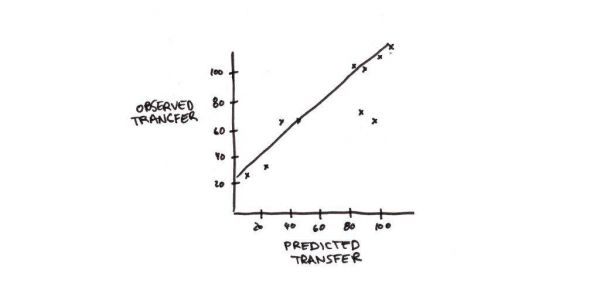
不过,迁移其实比 ACT-R 预测的还要好一些。拟合是线性的,但这种线性似乎从 26% 左右才开始表现出来。如果技能之间没有共享产生式的话,那么按照该理论,拟合应该从 0% 开始。安德森认为这可能是因为他们的技能模型漏掉了一些产生式。比方说,有些产生式可能牵涉到使用计算机,这种会在使用同一系统的任务之间进行迁移。
那更复杂的技能呢? ACT-R 认为,更抽象、更高层次的技能根据不同情况应该会有更好的迁移表现,因为底层的产生式还是保留下来的。因此设计算法这种技能应该可以在不同的编程语言之间迁移,因为就算实现算法的代码编写语法不一样,算法本质上都是一样的。
知识和理解呢? 在这方面 ACT-R 就不太能解释了。用于测试 ACT-R 理论的那种难题往往不需要大量的背景知识。由于学习的陈述性部分在研究的示例中进行得相对较快,所以不会占据迁移学习的主导。对于法律或医学等知识丰富的领域,可能存在不同的迁移模式,因为恰当地激活陈述性记忆系统变成了获得技能最耗时的部分。
一个多世纪以前,爱德华·桑戴克(Edward Thorndike)曾经提出,不同技能之间我们可以预期的迁移是因为它们包含有相同的元素。 ACT-R 本质上是这一理论的修订版,它认为桑戴克要找的元素就是产生式。
ACT-R 的内涵
大约在一年前,我开始对迁移进行深入研究。事实证明,这个问题比我一开始所意识到的要更深刻、更有趣。要想理解哪些知识发生了迁移,关键要取决于对“通过经验实际上学到什么?”这个问题的回答。
ACT-R 对这个核心问题提出了一个大胆主张:技能的基本单位就是产生式。实践产生新的产生式,并强化旧的产生式。技能迁移程度与这些产生式的叠合程度相关。
从中我们可以梳理出部分内涵:
大多数技能都是非常具体的。国际象棋策略不能迁移到商业战略上,因为它们之间几乎没有共同点。原则上,只要对任何两种技能进行微观分析,应该就可以告诉我们技能迁移可以到达什么样的程度。
相对于未来学习的测试,针对解决问题的测试的迁移要少一些。要想解决一个问题,你需要所有的产生式。获得一半的产生式并没有帮助,因为你缺少了前进所需的步骤。然而,拥有一半的产生式就能让学习的速度提高一倍,因为你要获得的新的产生式没那么多。学校往往并不会教授所有工作当中需要用到的技能,但结果未必就是悲观的。通过进一步的培训,人们可能会很快就学会使用相同成分的技能。
熟能生巧,但很多类型的实践也许纯属浪费。安德森偏爱智能辅导系统,当学生犯错时会立即纠正他们。计算机能不能胜任这项任务暂时有待讨论,但人类导师是目前已知的最有效的教学干预之一。
复杂的技能有简单的学习机制。尽管对产生式系统的描述看起来可能很复杂,但与我们经常执行的各种技能相比,这个系统还是非常简单的。机制简单说明,就算是最复杂的执行,理论上也可以分解成可学习的部分。唯一的困难是学习它们所需要投入的所有那些时间。
脚注:
ACT-R是理性思维的自适应控制(adaptive control of thought-rational, ACT-R),基础是安德森早期的 ACT* 模型。除非另有说明,否则所有材料均来自安德森描述 ACT-R 系统思维规则的书。ACT-R 是解释人类认知过程工作机理的理论。 该理论认为人类的认知过程需要四种不同的模块参与,即目标模块、视觉模块、动作模块和描述性知识模块。 每一个模块各自独立工作,并且由一个中央产生系统协调。 ACT-R 的核心是描述性知识模块和中央产生系统。
我在这里忽略了相对论,但牛顿力学仍然被认为是很好的相似物。
那条直线的下方有两个奇怪的异常值,这是因为研究人员想做一个负迁移的实验。这个实验是让人们学习使用一个文本编辑器,然后再让他们用一个虚构的、调换了很多命令的编辑器。这个实验表明,有时候旧技能会干扰学新东西,但迁移仍然为正这一事实表明,其实干扰并不像某些学习理论所说的那么严重。
译者:boxi。
相关推荐
学习复杂技能的大招:ACT-R 理论
成功的关键:我们应该学习何种技能?
神仙打架激辩深度学习:LeCun出大招,马库斯放狠话,机器学习先驱隔空“互怼”
柳传志最值得创业者学习的三个理论
如何找到适合当下的学习路径?新手学习三问
心流是什么?如何生发心流?心流理论极简入门版
AI要进一步发展,必须寻找“智能的通用理论”
谷歌“双十一”也放大招:Colab上可以免费使用P100 GPU了
你掌握的AI技能,可能并没有那么值钱
DeepMind最新论文:强化学习“足以”达到通用人工智能
网址: 学习复杂技能的大招:ACT-R 理论 http://www.xishuta.com/newsview63149.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



