搜索智能体的关键一课:先立目标,再照镜子

随着 AI 能力不断增强,它正日益融入我们的工作与生活。我们也更愿意给予它更多「授权」,让它主动去搜集信息、分析证据、做出判断。搜索智能体正是 AI 触达人类世界迈出的重要一步。
然而,现实世界的搜索环境并不总是「信息增益」的来源;它也可能放大微小偏差、把模型带入错误轨道。如何让搜索智能体在复杂环境中更稳健,成为关键问题。
近期,上海人工智能实验室及合作单位提出了一个简单而有效的思路:让搜索智能体像人一样,先「立目标」,再「照镜子」。具体而言,模型在每一次搜索前都要明确「我想找什么」(goal-oriented planning),搜索后再判断「是否找到」(self-reflection)。
我们将这一思路实现为 RE-Searcher,并在多个开放域问答与多跳推理任务上取得了新 SOTA 表现,同时显著提升了对环境噪声与搜索脆弱性的抵抗力。

论文标题:RE-Searcher: Robust Agentic Search with Goal-oriented Planning and Self-reflection论文链接:https://arxiv.org/abs/2509.26048
本文要点:
搜索环境是把双刃剑:既可能带来信息增益,也可能放大误差;RE-Searcher 通过「目标规划 + 自我反思」显式约束搜索路径,从错误轨迹中自我纠偏;在 7 个数据集上平均表现达到 SOTA 水平,并在干扰测试中表现出显著的稳健性。
「信息增益」 or 「误差增幅」
现实搜索并非总是「问一得十」。我们的分析表明,搜索环境的复杂性会显著放大模型固有的随机性,导致「同样的问题,跑两次,命运不同」的脆弱现象。
如图 1 所示,在相同数据上重复两次推理,弱一些的基础模型往往出现「随机正确」(random right)比例接近或甚至高于「总是正确」(always right)的情况。这种随机性极大削弱了模型的实际表现。这种不稳定的根源在于搜索过程的脆弱性。
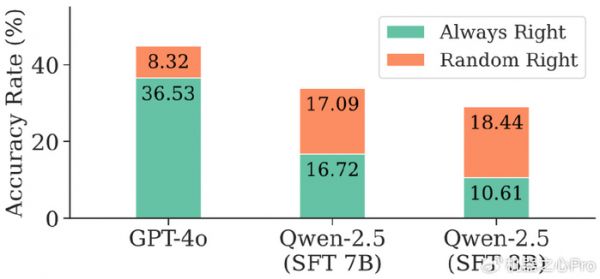
图 1. 模型回答随机性分析
如图 2 所示,只对检索式做细微改动(同义替换、增/删一词),检索结果的语义相似度就可能大幅下降,许多样本跌破 0.6 阈值。一个看似合理却偏离主题的关键词,足以把搜索引向错误分支。
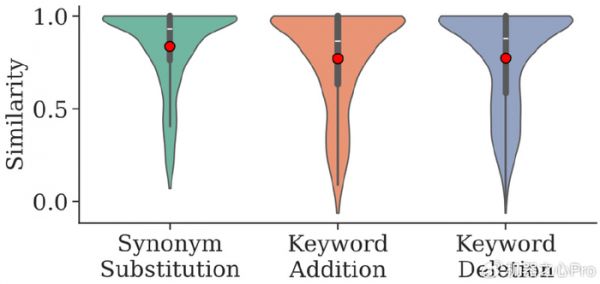
图 2. 搜索结果脆弱性分析
直观理解:如图 3 所示,把检索看作在「关键词图」上行走。一次小小的关键词变化,可能让智能体走进另一条支路;若后续优化都围绕这条错误分支展开,越走越偏,难以回到正确答案。强模型(如 GPT-4o)有时能「自救」,但更普遍、可落地的方式,是让模型从一开始就「立目标」,并在每一步都「照镜子」。
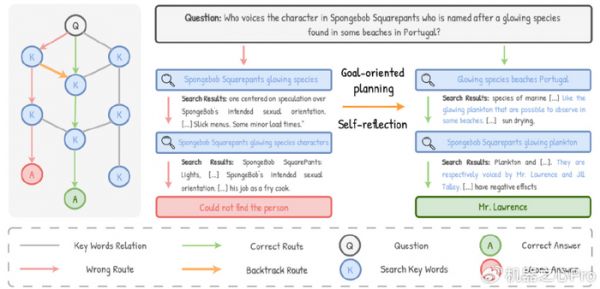
图 3. 搜索脆弱性分析
「立目标」与「照镜子」
为了让 AI 变得更稳健,研究团队提出了RE-Searcher框架。其核心思想是模仿人类在处理复杂任务时的两个关键认知行为:
「立目标」(Goal-Oriented Planning):在每次搜索前,不再是模糊地生成关键词,而是明确地规划出本次搜索想要达成的具体目标。「照镜子」(Self-Reflection):在获得搜索结果后,智能体必须进行反思,判断返回的信息是否满足了预设的目标。如果满足,则进入下一步;如果不满足,就需要调整搜索策略(比如修改关键词),重新搜索,直到达成目标为止。
为了实现这一点,如图 4 所示,研究团队设计了一套简单却有效的训练机制。他们通过特定的指令模板(如使用
、
、
标签)来规范智能体的思考和行为格式。
特别地,在「照镜子」环节,团队让一个「教师模型」(如 GPT-4o-mini)来评判智能体的反思是否正确,并将评价结果作为奖励信号,从而训练智能体学会如何进行高质量的自我反思。
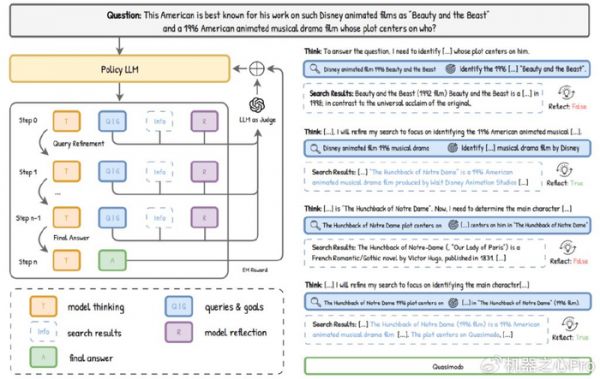
图 4. 训练 pipeline
小例子:经过训练的模型在一次多跳检索中,搜索引擎曾把关键词误解为同名小说;RE-Searcher 在反思环节判定「未满足目标」,只改了一个限定词就把结果拉回正轨。
实验结果:
更稳健的搜索智能体
为了验证 RE-Searcher 的效果,研究团队进行了一系列详尽的实验。
SOTA 表现与有效的反思行为
在包括 NQ、HotpotQA 在内的 7 个主流搜索问答数据集上,RE-Searcher 取得了领先的表现。无论是在 3B 还是 7B 模型规模上,RE-Searcher 的平均表现都超过了现有的基线模型,达到了新的SOTA(State-of-the-art)水平。
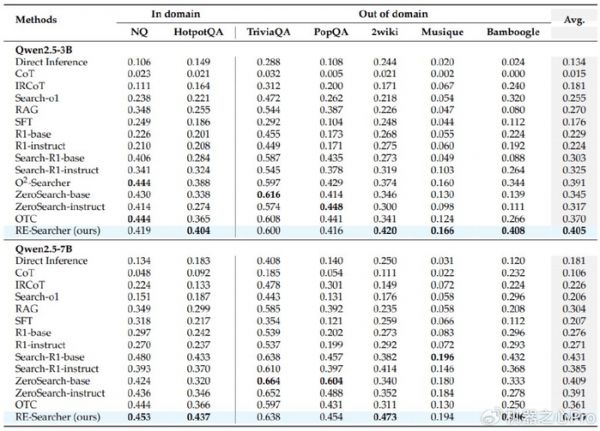
图 5. 主要性能表现
实验还证明了「反思奖励」的有效性。如果没有这个奖励,模型在反思时的判断准确率仅在 50% 左右(相当于随机猜测)。而加入奖励后,模型的反思能力得到了显著且稳定的提升。
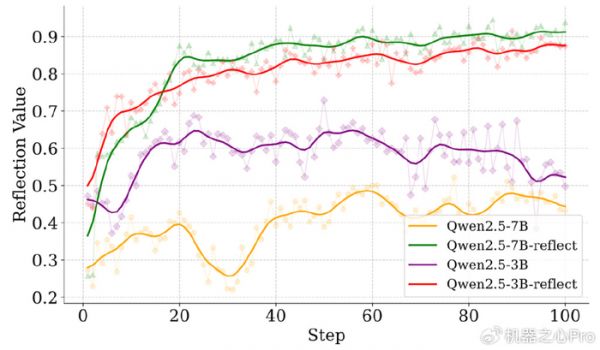
图 7. 反思正确率变化曲线
有效抵抗「搜索脆弱性」
RE-Searcher 能否缓解前面提到的「随机正确」问题?答案是肯定的。
实验数据显示,经过训练后,RE-Searcher 的「随机正确」比例大幅降低。以 7B 模型为例,其「随机正确」率从 SFT(监督微调)模型的17.09%降低到了8.74%,几乎减半,并且非常接近能力更强的 GPT-4o 的水平(8.32%)。这表明,智能体不再是「凭运气」答对,而是真正具备了稳定解决问题的能力。
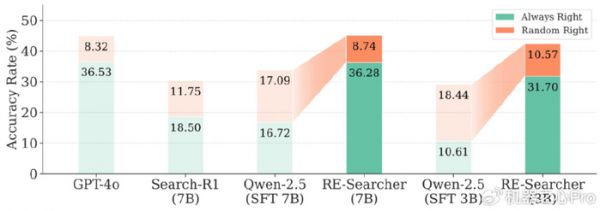
图 8. 随机性变化效果
面对外部干扰,表现更「淡定」
为了模拟真实世界中更极端的噪声,研究团队设计了一个「压力测试」:在智能体的第一次搜索时,人为地向其搜索查询中引入干扰(如随机增删或替换词语),观察其性能下降程度。
结果显示,RE-Searcher 表现出了极强的鲁棒性。与基线模型 Search-R1 相比,RE-Searcher (7B) 的性能下降幅度要小得多(12.73%vs21.30%),几乎与 GPT-4o 处于同一水平。这证明了「立目标、照镜子」的策略使其不容易被初期的错误信息带偏,具备更强的纠错和恢复能力。
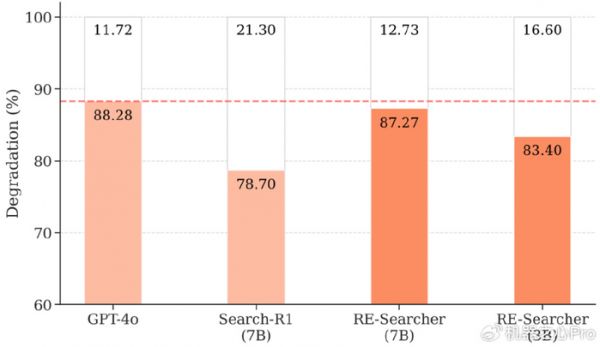
图 9. 抗干扰实验结果展示
未来展望
RE-Searcher 的研究证明,通过教会 AI 智能体进行目标规划和自我反思,可以显著提升其在复杂环境中的稳健性和可靠性。随着我们给予 AI 越来越多的自主权,它们将不可避免地与更加动态和不可预测的真实世界环境进行交互。如何确保它们在这一过程中行事稳健、值得信赖,是一个需要持续探索的重要课题。这项工作为构建更强大、更负责任的自主智能体迈出了坚实的一步。
发布于:北京
相关推荐
周鸿祎的搜索梦 纳米AI搜索担不起
智能体迈入L4时代,纳米AI多智能体蜂群,可创作史上最长10分钟AI视频
智能体迎来“DeepSeek时刻”,为何主角是纳米AI?
多智能体的协作悖论
能赚钱的智能体,已经来了!
OpenAI发布首个AI智能体,有哪些不一样?
今年首批AI智能体有望“就业”?国产办公智能体再升级
AI搅动美国电商圈:高管频繁互挖,智能体购物已经共识
Claude新指南,教你构建属于自己的智能体
智能体崛起
网址: 搜索智能体的关键一课:先立目标,再照镜子 http://www.xishuta.com/newsview143494.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



