OpenAI红色警报下的反击:发布GPT-5.2迎战Gemini 3
(来源:DeepTech深科技)
当谷歌的 Gemini 在各大 AI 排行榜上风头正劲时,OpenAI 终于打出了新的王牌。
周四,这家 AI 巨头发布了 GPT-5.2,称其是迄今为止“最强大的模型”,专为开发者和职场人士打造。
 (来源:OpenAI)
(来源:OpenAI)这场发布会的时机颇为微妙。
一个月前,OpenAI CEO 山姆·奥特曼(Sam Altman)向内部发出“红色警报”,承认 ChatGPT 面临巨大竞争压力,正在输掉消费市场份额。今天的 GPT-5.2 正是 OpenAI 试图夺回领导地位的关键一步。
同时,今天也是 OpenAI 官宣成立十周年的日子。
GPT-5.2 模型家族包括三个不同版本:Instant、Thinking 和 Pro。
Instant 是速度优化版本,专门处理日常查询,比如信息检索、写作和翻译这类常规任务。
Thinking 则擅长复杂的结构化工作,在编程、分析长文档、数学计算和项目规划方面表现突出。
Pro 则是顶级版本,旨在为最棘手的问题提供最高精度和可靠性。它的运行速度显著慢于其他版本,且成本极其高昂,专为那些准确性高于一切、成本退居其次的重要任务设计。
测试数据表明,Pro 版本是唯一在 ARC-AGI-1 推理基准测试中突破 90% 大关,并在 AIME 2025 数学竞赛中不使用工具就达到 100% 满分的模型。
在 ChatGPT 中,GPT-5.2 的三个版本已经上线,首先面向付费用户开放。OpenAI 表示将在未来几天逐步部署 GPT-5.2,以保持 ChatGPT 尽可能流畅和可靠。
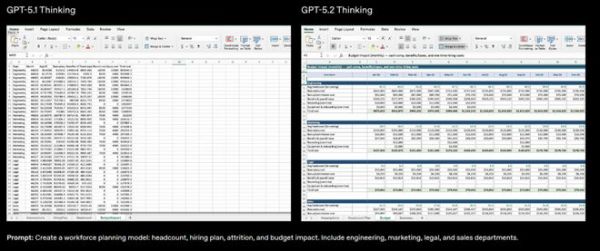
“我们设计 GPT-5.2 就是为了给人们创造更多经济价值。”OpenAI 应用业务 CEO 菲吉·西莫(Fidji Simo)在发布会上表示。她强调,新模型在创建电子表格、制作演示文稿、编写代码、图像识别、理解长文本、使用工具以及处理复杂多步骤项目方面都有显著提升。
 (来源:OpenAI)
(来源:OpenAI)据其介绍,ChatGPT 企业版的普通用户表示“AI 每天为他们节省 40-60 分钟”,而重度用户每周节省时间“超过十小时”。GPT-5.2 的目标就是进一步扩大这种价值。
OpenAI 表示,GPT-5.2 在多项行业基准测试中创下新纪录。
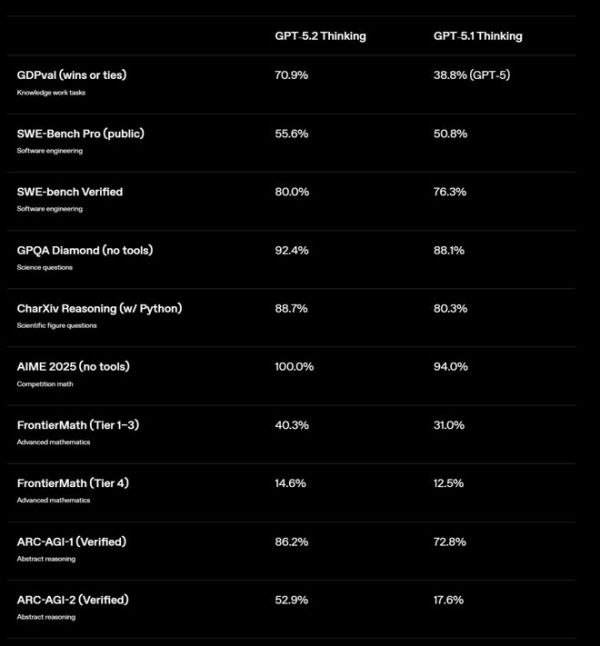 图 | 多项基准测试成绩(来源:OpenAI)
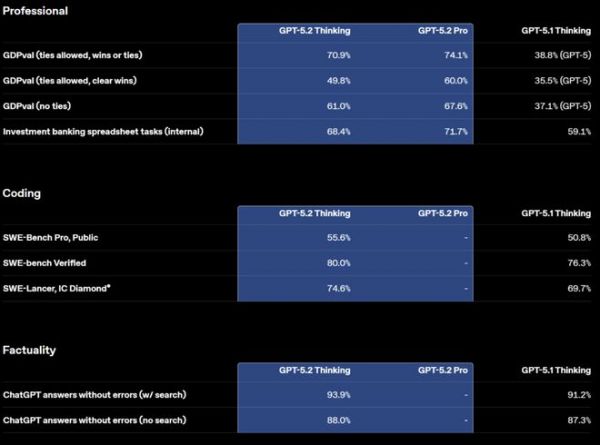
图 | 多项基准测试成绩(来源:OpenAI)在涵盖 40 多种职业专业知识的 GDPval 测试中,GPT-5.2 Thinking 的表现达到了专家级水平。根据专业评审的判断,在 70.9% 的情况下,GPT-5.2 Thinking 击败或打平了顶级行业专业人士。这些任务包括制作演示文稿、电子表格和其他各类工作成果。
更重要的是,GPT-5.2 完成这些任务的速度是专业人士的 11 倍以上,成本却不到 1%,不过 OpenAI 并未公布模型 VS 人类的成本是如何计算的。
 (来源:OpenAI)
(来源:OpenAI)在软件工程领域,GPT-5.2 Thinking 在 SWE-Bench Pro 测试中达到了 55.6% 的新高分。这个成绩也是超过了 Claude 4.5 Sonnet 和 Gemini 3 Pro。在更基础的 SWE-bench Verified 测试中,GPT-5.2 的得分更是达到了 80%。
 (来源:资料图)
(来源:资料图)OpenAI 研究主管艾丹·克拉克(Aidan Clark)解释说,更强的数学能力不仅仅是解方程那么简单。数学推理能力是衡量模型能否遵循多步骤逻辑、保持数字长期一致性、避免可能随时间累积的细微错误的代理指标。
在科学问题方面,GPT-5.2 Pro 在 GPQA Diamond 测试中取得了 93.2% 成绩。GPT-5.2 Thinking 也有 92.4% 的高分。双双打破了 Gemini 3 Pro 保持的纪录。
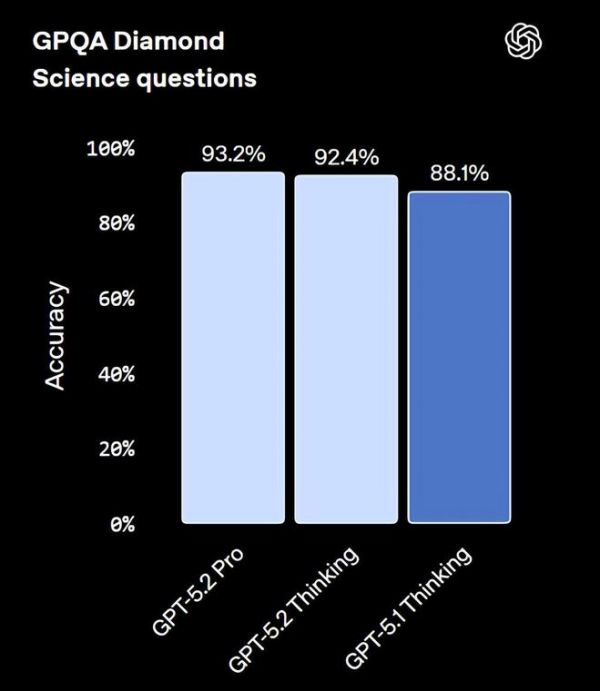
克拉克在发布会上分享了一个案例:团队让一位资深免疫学研究员使用 GPT-5.2 Pro,当研究员要求模型生成关于免疫系统最重要的未解问题时,模型产生了“更敏锐的问题和更有力的解释”,用于说明这些问题为何重要。该研究员认为其表现超过了“所有其他前沿模型”。
在可靠性方面,GPT-5.2 也取得了重要进展。OpenAI 后训练负责人马克斯·施瓦策(Max Schwarzer)指出,在衡量对事实性问题回答的基准测试中,GPT-5.2 Thinking 的幻觉出现率比 GPT-5.1 降低了 38%。
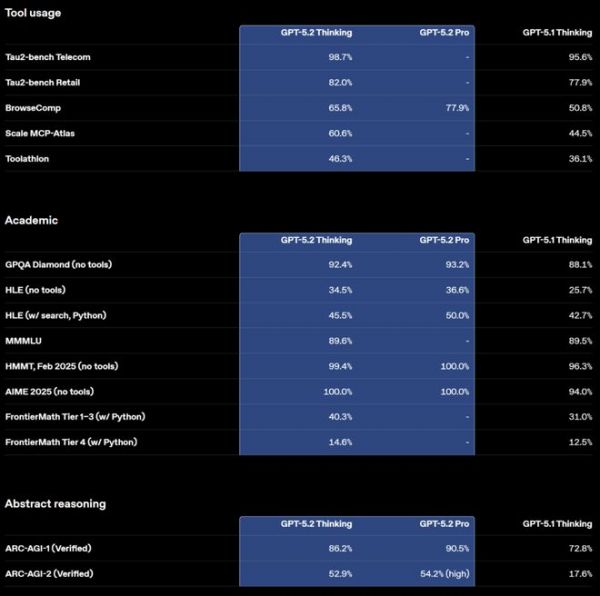 (来源:OpenAI)
(来源:OpenAI)长文本理解方面,GPT-5.2 Thinking 同样创下了新纪录。OpenAI 采用 MRCRv2 评估来衡量模型整合分散在长文档中信息的能力。
处理需要跨越数十万 token 相关信息的真实任务时,GPT-5.2 Thinking 的准确性远超 GPT-5.1 Thinking。它是第一个在四针 MRCRv2 测试中(最多 256k token)实现接近 100% 准确率的模型。
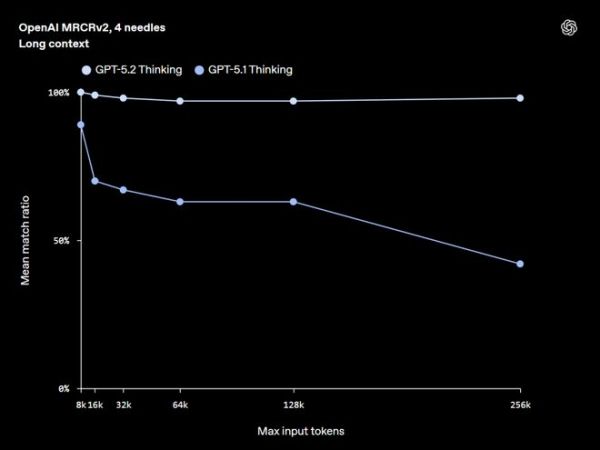 (来源:OpenAI)
(来源:OpenAI)这意味着专业人士可以更放心地使用 GPT-5.2 处理长文档,如报告、合同、研究论文、记录和多文件项目,同时在数十万 token 范围内保持连贯性和准确性。
在视觉能力方面,GPT-5.2 Thinking 在图表推理和软件界面理解方面的准确率提升近 50%。这意味着模型可以更准确地解读仪表板、产品截图、技术图表和可视化报告,支持更加依赖视觉信息的工作流。
相比之前的模型,GPT-5.2 Thinking 对图像中元素位置的把握更强。例如,在识别主板图像中的组件并返回大致边界框的任务中,即使在低质量图像上,GPT-5.2 也能识别主要区域并放置与每个组件真实位置有时匹配的框,而 GPT-5.1 只能标记少数部分,对空间排列的理解要弱得多。
 (来源:OpenAI)
(来源:OpenAI)值得一提的是,OpenAI 的新图像生成工具仍然缺位。据报道,奥特曼曾在内部红色警报备忘录中表示,图像生成将是未来的重点,特别是在谷歌的新版 Nano Banana 发布之后。
据报道,OpenAI 计划在明年一月发布另一款新模型,具有更好的图像效果、更快的速度和更好的个性,但尚未得到官方确认。
最后在发布会上,OpenAI 承认在某些方面还有改进空间。比如在 ChatGPT 中,公司正在努力解决过度拒绝等已知问题,同时继续提高回复的可靠性。此外,OpenAI 据传正在考虑开放模型成人内容限制。
对于 OpenAI 来说,GPT-5.2 能否帮助它重新夺回失去的领地,还需要时间来证明。
参考资料:
https://openai.com/index/introducing-gpt-5-2/
https://www.theverge.com/ai-artificial-intelligence/842529/openai-gpt-5-2-new-model-chatgpt
https://techcrunch.com/2025/12/11/openai-fires-back-at-google-with-gpt-5-2-after-code-red-memo/
相关推荐
OpenAI提前发布GPT-5.2反击谷歌Gemini3
OpenAI“红色警报”全线启动,代号“Garlic”的GPT‑5.5冲击Gemini3
OpenAI会是第一个倒闭的AI独角兽吗?
OpenAI发布GPT5.2模型,创多项行业记录
一句话生成3D小游戏!谷歌Gemini 3的“领先”迫使OpenAI提前出手
Gemini灵魂人物加盟xAI,马斯克亲自夹道欢迎!
谷歌发动对OpenAI的最强反击
Gemini发布仅一天就遭质疑,谷歌追赶OpenAI太过心急?
谷歌想用Gemini拳打OpenAI,用Gemma脚踢Meta
Google成了“AI界汪峰”,全都怪OpenAI?
网址: OpenAI红色警报下的反击:发布GPT-5.2迎战Gemini 3 http://www.xishuta.com/newsview145176.html
推荐科技快讯







- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



